Our Editors-in-Chief’s Top Picks
The Editors-in-Chief of our CASS publications have selected some noteworthy papers from the recent issues of our journals:
IEEE Transactions on Circuits and Systems II: Express Briefs
Paper 1:
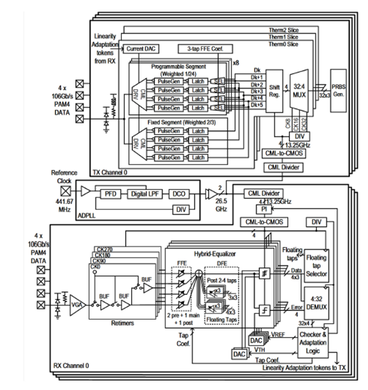
B. Zhang, T. Ye, Z. Wang, X. Liu, T. Zhong, R. Wang, and W. Gai, “A 4×106 Gb/s Mixed-Signal PAM-4 Transceivers for Optical Direct-Detect Applications With Adaptive Linearity Compensation in 28-nm CMOS”, IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 72, no. 5, pp. 728 – 732, May. 2025. doi: 10.1109/TCSII.2025.3557793. https://ieeexplore.ieee.org/document/10949626
Summary: This work presents a 4x106Gb/s mixed-signal PAM-4 transceivers fabricated in 28nm CMOS in this brief to reduce cost, area and power consumption. The transceiver supports adaptive linearity compensation with analog PAM4 level pre-distortion technique in TX. 4-tap FFE and 7-tap DFE including 4 floating taps are implemented in RX to take DFE’s advantage of not amplifying noise thanks to the mixed-signal structure. The transceiver achieves an optical sensitivity of -8.7dBm, which is 0.7dBm better than the DSP-based equalization methods under the same optical test environment. The energy efficiency and single-channel area are 4.42pJ/bit and 0.28mm2 respectively, both of which are better than reported 100Gb/s counterparts.
Paper 2:
Y. Kwon, J. Won, B. Min, D. Kim, J. Kim, J-H. Yang, and Y. Chae, “A 10-Bit 500-MS/s Pipelined SAR ADC With Feedback Factor Compensation in 6-nm FinFET”, IEEE Transactions on Circuits and Systems—II: Express Briefs, vol. 72, no. 5, pp. 698 – 702, May 2025. doi: 10.1109/TCSII.2025.3554297. https://ieeexplore.ieee.org/document/10938244
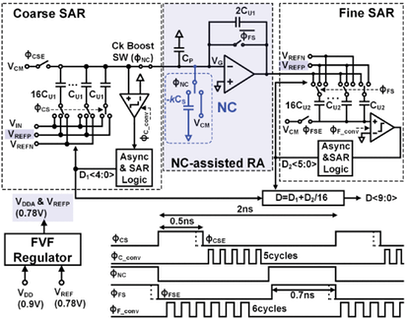
Summary: This brief introduces an energy-efficient 10-bit 500-MS/s pipelined SAR ADC that uses feedback factor compensation in 6-nm FinFET technology. The design challenges of residue amplifier in FinFET technology are adequately addressed by incorporating feedback factor compensation. This enables the use of an inverter-based residue amplifier that can achieve a high-speed operation of 500-MS/s at a low supply voltage of 0.9 V. The prototype ADC is fabricated in a 6-nm FinFET and occupies 0.014 mm2 . With a Nyquist input signal, it achieves an SNR of 54.2 dB and an SNDR of 53.6 dB, while consuming 2.7 mW from a 0.9 V supply voltage. This brief achieves a competitive Walden figure of merit (FoM) of 13.8 fJ/conv.-step.
Paper 3:
Jiajun Tang, Xiyuan Tang, “A 12.6-pJ/Conversion Temperature Sensor With 0.98-mV/K Temperature-Voltage Sensitivity”, IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 72, no. 4, pp. 449 - 453, Apr. 2025. doi: 10.1109/TCSII.2025.3530257. https://ieeexplore.ieee.org/document/10843399
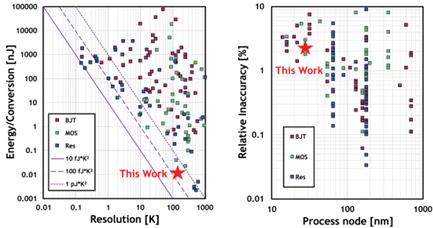
Summary: This brief proposes a low-power and energy-efficient CMOS temperature sensor circuit. It presents an integrated transducer and readout design with a novel 1-bit temperature-voltage (T-V) comparator-embedded 12-bit SAR ADC. Thanks to the proposed load-capacitor-imbalance technique, the temperature-voltage sensitivity is increased, thus improving system energy efficiency. Implemented in a 28nm CMOS, it consumes 12.6-pJ per conversion, achieving a 0.15K resolution under a 0.6-V power supply, thus realizing a state-of-the-art resolution Figure-of-Merit (FoM) of 0.29-pJ ⋅ K^2.
IEEE Transactions on Circuits and Systems for Video Technologies
Paper 1:
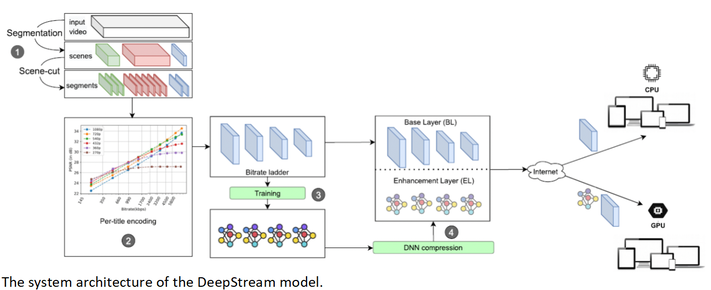
H. Amirpour, M. Ghanbari and C. Timmerer, "DeepStream: Video Streaming Enhancements Using Compressed Deep Neural Networks," IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 4, pp. 3786-3797, April 2025, doi: 10.1109/TCSVT.2022.3229079 https://ieeexplore.ieee.org/document/9984695
Summary: This paper proposes a scalable content-aware per-title encoding approach, called DeepStream, to support both CPU-only and GPU-available end-users. To support backward compatibility, DeepStream constructs a bitrate ladder based on any existing per-title encoding approach. Therefore, the video content is provided for legacy end-user devices with CPU-only capabilities as a base layer (BL). For high-end end-user devices with GPU capabilities, an enhancement layer (EL) is added on top of the base layer comprising lightweight video super-resolution deep neural networks (DNNs) for each bitrate-resolution pair of the bitrate ladder. A content-aware video super-resolution approach leads to higher video quality, at the cost of bitrate overhead. To reduce the bitrate overhead for streaming content-aware video super-resolution DNNs, DeepCABAC, context-adaptive binary arithmetic coding for DNN compression, is used. Furthermore, the similarity among segments within a scene and frames within a segment are used to reduce the training costs of DNNs. Experimental results show bitrate savings of 34% and 36% to maintain the same PSNR and VMAF, respectively, for GPU-available end-users, while the CPU-only users get the desired video content as usual.
Paper 2:
K. Fischer, F. Brand and A. Kaup, "Boosting Neural Image Compression for Machines Using Latent Space Masking," IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 4, pp. 3719-3731, April 2025, doi: 10.1109/TCSVT.2022.319532 https://ieeexplore.ieee.org/document/9845478
Summary: This paper presents several methods to enhance the compression performance of Neural Compression Networks (NCNs) when coding for a neural network as information sink by sacrificing visual quality. As a main contribution, this paper proposes a network, called LSMnet, that runs in parallel to an encoder network and masks out elements of the latent space that are presumably not required for the analysis network. By this approach, additional 27.3% of bitrate are saved compared to the basic neural compression network optimized with the task loss. A feature-based distortion is also utilized in the training loss within the context of machine-to-machine communication, which allows for a training without annotated data. Analyses is reported on the Cityscapes dataset including cross-evaluation with different analysis networks and exemplary visual results are also shown..
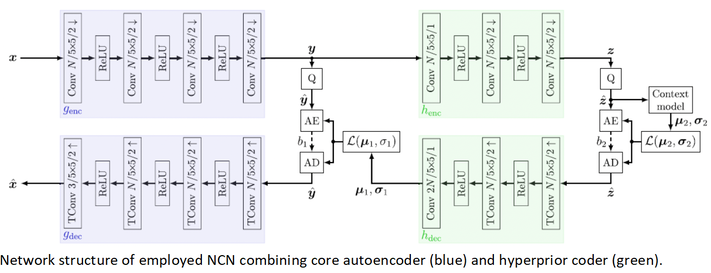
Paper 3:
H. Sun, L. Yu and J. Katto, "Q-LIC: Quantizing Learned Image Compression With Channel Splitting," IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 4, pp. 3798-3811, April 2025, doi: 10.1109/TCSVT.2022.3231789 https://ieeexplore.ieee.org/document/9997555
Summary: This paper presents a Quantized Learned Image Compression (QLIC) by channel splitting. First, it is explored that the influence of the quantization error to the reconstruction error is different for various channels. Second, the channels are split whose quantization has larger influence to the reconstruction error. After the splitting, the dynamic range of channels is reduced so that the quantization error can be reduced. Finally, several channels are pruned to keep the number of overall channels as origin. By using the proposal, in the case of 8-bit quantization for weight and activation of both main and hyper path, the BD-rate is reduced by 0.61%-4.74% compared with the previous QLIC. Better coding gain can be reached compared with the state-of-the-art network quantization method when quantizing MS-SSIM models. This proposed solution can be also combined with other network quantization methods to further improve the coding gain. The moderate coding loss caused by the quantization validates the feasibility of the hardware implementation for QLIC in the future.
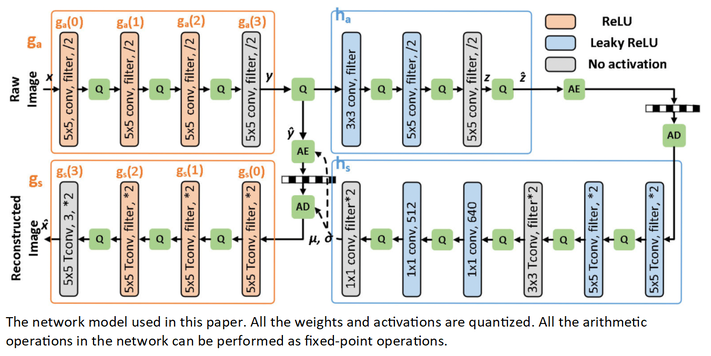
IEEE Transactions on Very Large Scale Integration (VLSI) Systems
Paper 1:
Das, S., Riedel, S., Naeim, M., Brunion, M., Bertuletti, M., Benini, L., Ryckaert, J., Myers, J., Biswas, D. and Milojevic, D., 2024. "Bandwidth-Latency-Thermal Co-Optimization of Interconnect-Dominated Many-Core 3D-IC," IEEE Transactions on Very Large Scale Integration (VLSI) Systems. vol. 33, no. 2, pp. 346-357, Feb. 2025, doi: 10.1109/TVLSI.2024.3467148 https://ieeexplore.ieee.org/document/10720515
Summary: The article addresses the challenges faced by contemporary system-on-chips (SoCs) due to the increasing demands for memory bandwidth, capacity, and thermal stability, particularly in the context of advancing artificial intelligence (AI). It proposes architectural modifications for a many-core SoC designed to enhance on-chip cache memory bandwidth and optimize access latency. The SoC is fabricated using A10 nanosheet technology in a 3-D configuration, with thermal analyses conducted. Workload simulations demonstrate significant performance improvements, achieving up to 12-fold acceleration for a 64-core version and 2.5-fold for a 16-core version, accompanied by a 40% increase in die area and a 60% rise in power dissipation when using a 2-D design. In comparison, the 3-D design not only minimizes the physical footprint but also saves 20% in power consumption due to a 40% reduction in wirelength. The study emphasizes the importance of restructuring pipelines to optimize the benefits of 3-D technology for enhanced memory access and lower latency. Additionally, it explores thermal impacts of different 3-D partitioning approaches in high-performance computing (HPC) and mobile applications, finding that 3-D designs in mobile contexts only slightly increase maximum temperature (by about 2-3 °C) compared to 2-D, while HPC scenarios require careful partitioning strategies to effectively manage thermal constraints.
Paper 2:
G. Murali, M. Gyu Park and S. Kyu Lim, "3DNN-Xplorer: A Machine Learning Framework for Design Space Exploration of Heterogeneous 3-D DNN Accelerators," IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 33, no. 2, pp. 358-370, Feb. 2025, doi: 10.1109/TVLSI.2024.3471496. https://ieeexplore.ieee.org/document/10715720
Summary: This paper introduces 3DNN-Xplorer, a novel machine learning (ML)-based framework for predicting the performance of heterogeneous 3-D deep neural network (DNN) accelerators. This framework enables design space exploration (DSE) of these accelerators with a two-tier compute-on-memory (CoM) configuration, considering 3-D physical design factors. The framework explores four distinct heterogeneous 3-D integration styles combining 28-nm and 16-nm technology nodes for both compute and memory tiers. Through extrapolation techniques and ML models trained on various accelerator configurations, the performance of larger systems is estimated, achieving a maximum absolute error of 13.9%. The framework considers area imbalance arising from different technology nodes by assuming equal numbers of PEs or on-chip memory capacity across integration styles. The analysis reveals that the heterogeneous 3-D style with 28-nm compute and 16-nm memory demonstrates energy-efficient performance, offering up to 50% energy savings and an 8.8% reduction in runtime compared to other 3-D integration styles. Conversely, the heterogeneous 3-D style with 16-nm compute and 28-nm memory proves area-efficient, exhibiting up to 8.3% runtime reduction compared to other 3-D styles.
Paper 3:
A. Almeida da Silva, L. Nogueira, A. Coelho, J. A. N. Silveira and C. Marcon, "Securet3d: An Adaptive, Secure, and Fault-Tolerant Aware Routing Algorithm for Vertically–Partially Connected 3D-NoC," IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 33, no. 1, pp. 275-287, Jan. 2025, doi: 10.1109/TVLSI.2024.3500575 https://ieeexplore.ieee.org/document/10766899
Summary: This article presents Securet3d, a novel routing algorithm designed for multiprocessor systems-on-chip (MPSoCs) that utilize 3-D networks-on-chip (3D-NoCs), aimed at enhancing secure and fault-tolerant operations. As MPSoCs play a crucial role in achieving effective parallel computing by sharing resources across complex applications, implementing adaptive mechanisms to safeguard sensitive data is essential. Securet3d builds upon the existing Reflect3d algorithm, introducing a comprehensive mapping scheme for secure data pathways and improving the system’s fault tolerance. The algorithm's effectiveness is validated through comparisons with three other fault-tolerant routing algorithms in vertically-partially connected 3D-NoCs. All algorithms were developed in SystemVerilog and evaluated via simulations using ModelSim, and hardware synthesis was performed with Cadence’s Genus tool. The experimental results indicate that Securet3d not only reduces latency but also enhances cost-effectiveness compared to other methods. Implemented with a 28-nm technology library, Securet3d exhibits minimal area and energy overhead, demonstrating its scalability and efficiency. Moreover, during denial-of-service (DoS) attacks, Securet3d maintains relatively stable average packet latencies of 70, 90, and 29 clock cycles for uniform random, bit-complement, and shuffle traffic, respectively, which are significantly lower than the latencies observed in other algorithms lacking security mechanisms (5763, 4632, and 3712 clock cycles on average). These findings underscore Securet3d's superior security, scalability, and adaptability for complex communication systems.
IEEE Journal on Emerging and Selected Topics in Circuits and Systems
Paper 1:
M. Ghasempour, H. Amirpour and C. Timmerer, "Real-Time Quality- and Energy-Aware Bitrate Ladder Construction for Live Video Streaming," IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 15, no. 1, pp. 83-93, March 2025, doi: 10.1109/JETCAS.2025.3539948. [It's open access!]
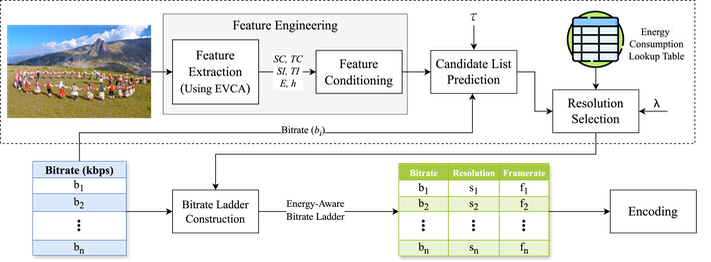
Summary: The increasing demand for high-quality live video streaming has heightened energy inefficiencies in traditional encoding methods. The authors propose LiveESTR, a lightweight, energy-efficient method for dynamic bitrate ladder construction in live video streaming that effectively balances quality and energy consumption without compromising latency. LiveESTR reduces encoder and decoder energy consumption by 74.6% and 29.7%, respectively, with only a 2.1% BD-Rate increase compared to per-title encoding.
Paper 2:
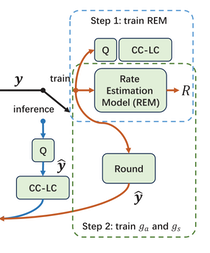
R. Yang, D. Liu, F. Wu and W. Gao, "Learned Image Compression With Efficient Cross-Platform Entropy Coding," IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 15, no. 1, pp. 72-82, March 2025, doi: 10.1109/JETCAS.2025.3538652.
Summary: Existing learned image compression methods rely on neural network-based entropy models, which face challenges such as high computational complexity and cross-platform inconsistencies. This paper presents an efficient entropy coding method called Chain Coding-based Latent Compression (CC-LC) and introduces a surrogate rate estimation model for end-to-end learning. The proposed method significantly reduces entropy coding complexity while achieving compression efficiency comparable to BPG.
Paper 3:
A. Mercat, J. Sainio, S. Le Moan and C. Herglotz, "Do We Need 10 bits? Assessing HEVC Encoders for Energy-Efficient HDR Video Streaming," IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 15, no. 1, pp. 31-43, March 2025, doi: 10.1109/JETCAS.2025.3533041. [It's open access!]
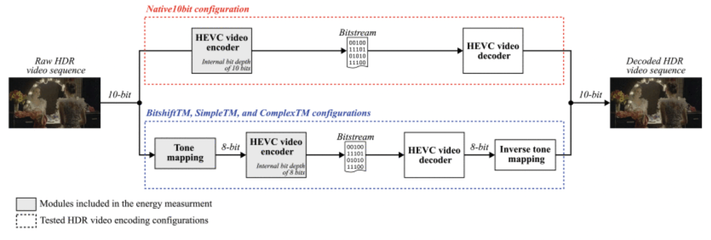
Summary: High dynamic range (HDR) content boosts video viewing experience but its expanded bit depth increases encoder energy consumption. This study evaluates tone mapping as a bit-depth reduction strategy across all presets of three open-source HEVC encoders to mitigate the energy cost. Our results show that tone mapping has potential for reducing the encoding energy, but further study into the topic is still needed.
IEEE Open Journal of Circuits and Systems
Paper 1:
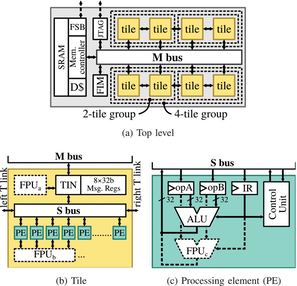
T. Kaiser, E. Gottschalk, K. Biethahn and F. Gerfers, "Pasithea-1: An Energy-Efficient Sequential Reconfigurable Array With CPU-Like Programmability," IEEE Open Journal of Circuits and Systems, vol. 6, pp. 1-13, 2025, doi: 10.1109/OJCAS.2024.3518110. https://ieeexplore.ieee.org/document/10802954
Summary: This work presents Pasithea-1, a coarse-grained reconfigurable array (CGRA) that combines energy efficiency with CPU-like programmability.
Paper 2:
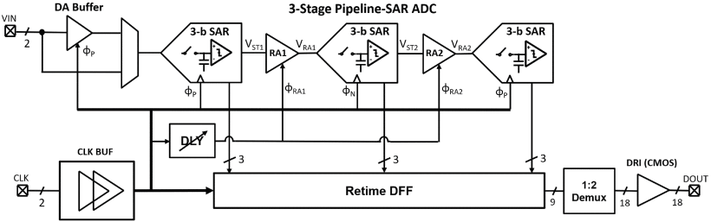
B. Yang, T. Caldwell and A. Chan Carusone, "An Energy-Efficient Pipeline-SAR ADC Using Linearized Dynamic Amplifiers and Input Buffer in 22nm FDSOI," IEEE Open Journal of Circuits and Systems, vol. 6, pp. 50-62, 2025, doi: 10.1109/OJCAS.2024.3509746. https://ieeexplore.ieee.org/document/10774063
Summary: This work presents a dynamic amplifier that achieves −52 dB in total harmonic distortion through an analog technique by which the expanding and compressing nonlinearities in the input transistors cancel one another. A pipeline-SAR analog-to-digital converter incorporating the linearized dynamic amplifier in both the input buffer and the first residue amplifier stage was designed and fabricated using the GlobalFoundries 22nm fully depleted silicon-on-insulator process.
Paper 3:
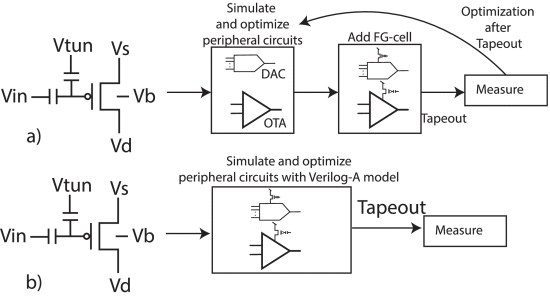
S. Nowshin Chowdhury, M. Chen and S. Shah, "Analysis and Verilog-A Modeling of Floating-Gate Transistors," IEEE Open Journal of Circuits and Systems, vol. 6, pp. 63-73, 2025, doi: 10.1109/OJCAS.2024.3524363. https://ieeexplore.ieee.org/document/10818976
Summary: This work presents a Verilog-A model based on empirical measurements for a floating-gate transistor fabricated using a 65 nm CMOS process.
________________
IEEE CAS Magazine Second Quarter Issue 2025

Now available: Second Quarter Issue
IEEE Circuits and Systems (CAS) Magazine publishes original review articles and other articles that are of broad interest to the Circuits and Systems Society community. Interested authors are invited to send a three to four page White Paper first to the Editor-in-Chief, Prof. Keshab K. Parhi, by email here. If invited, they can submit a Full Paper at the Author Portal at the link below. CAS Magazine will continue to publish articles related to CAS Society Outreach. In addition, CAS Magazine also publishes articles related to education (such as tricks in solving problems and short lecture notes), conference highlights, chapter highlights, applications, and standards. Please feel free to submit articles that are of broad interest to the members of the CAS Society. For more information, please visit the IEEE Circuits and Systems Magazine on the CASS website.
________________
Active "Call for Papers” Archive

______________________________
Latest Tables of Contents of CAS Sponsored Journals
The latest issues of our CAS sponored journals have been published and the tables of contents can be accessed through the following links:

- IEEE Transactions on Circuits and Systems I: Regular Papers
- IEEE Transactions on Circuits and Systems II: Express Briefs
- IEEE Transactions on Circuits and Systems for Video Technology
- IEEE Journal on Emerging and Selected Topics in Circuits and Systems
- IEEE Circuits and Systems Magazine
- IEEE Transactions on Biomedical Circuits and Systems
- IEEE Design and Test Magaz