Our Editors-in-Chief’s Top Picks
The Editors-in-Chief of our CASS publications have selected some noteworthy papers from the recent issues of our journals:
IEEE Transactions on Circuits and Systems I: Regular Papers
Paper 1:
S. Nooshabadi and A. Hajimiri, "Phase Noise and Dynamic Range in Radar Arrays," IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 72, no. 9, pp. 4610-4623, Sept. 2025, doi: 10.1109/TCSI.2025.3526365. https://ieeexplore.ieee.org/document/10849942
Summary: Antenna arrays are highly prevalent in mm-Wave automotive radar. A major power consumer in these systems is the local oscillator (LO) generation and distribution. Understanding the effects of LO phase noise on the radar array is essential due to its intimate dependence on the power consumption of the signal generation network. In this work, we present an analytical framework that predicts the influence of LO phase noise on the output spectrum of an arbitrary radar array. The framework reveals how system-level parameters, such as radar codes, array configuration, etc., influence the dynamic-range-limiting sidelobes in the radar output spectrum.
Paper 2:
M. Jara and B. Razavi, "A Predictive SAR ADC Architecture," IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 72, no. 9, pp. 4513-4526, Sept. 2025, doi: 10.1109/TCSI.2025.3525619. https://ieeexplore.ieee.org/document/10833702
Summary: In today’s digital works, analog-to-digital converters (ADCs) have a critical role to convert analog signals into digital data. High-speed ADCs are especially vital in modern communication systems, where every picosecond counts. Despite their speed limitations, successive approximation (SAR) ADCs remains as an attractive solution due its simple design and power efficiency. In this work, we exploit the binary search nature of SAR ADC to predict future residue voltages. By anticipating these calculations, the main internal blocks can operate in parallel rather than sequentially, significantly improving the conversion rate. This new approach enhances performance, making it well suited for high-speed receiver designs.
IEEE Transactions on Circuits and Systems II: Express Briefs
Paper 1:
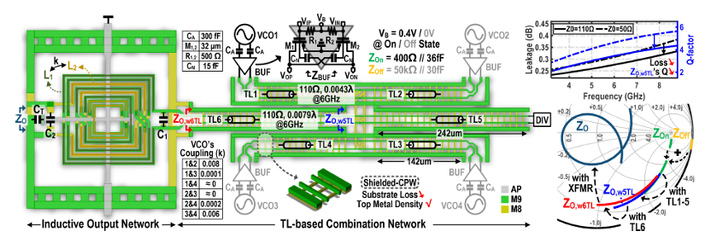
X. Liao, D. Zhao, C. Xu, H. Gong and X. You, “A 3.9-8.2-GHz Wideband Frequency Synthesizer With an Inductive Multiplexing Output Network for SATCOM Applications,” IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 72, no. 9, pp. 1163 – 1167, Sept. 2025. doi: 10.1109/TCSII.2025.3590593 https://ieeexplore.ieee.org/document/11084881
Summary: This paper presents a wideband frequency synthesizer with 3.9 to 8.2 GHz continuous frequency coverage for satellite communication applications. The core fractional-N phase locked loop utilizes four LC-VCOs achieving a 4.3 GHz tuning range. A high-isolation low-loss inductive multiplexing output technique is proposed, which uses only one active buffer to drive both the internal loop and the external load, significantly reducing power consumption. Fabricated in a 65-nm CMOS technology, the frequency synthesizer occupies a chip area of 2.28 mm2 while consumes power of 25–33.5 mW. The phase noise reaches –123.72 dBc/Hz and –116.31 dBc/Hz at 1-MHz offset under 3.9- and 8.2-GHz carriers, respectively.
Paper 2:
J. Jo, J. Jung, and K. J. Lee, “An Energy-Efficient Image Deblurring Accelerator With Quad-Base-Quad-Scale Quantized Format and Layer Normalization-Aware Optimization,” IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 72, no. 9, pp. 1273 – 1277, Sept. 2025. doi: 10.1109/TCSII.2025.3586657 https://ieeexplore.ieee.org/document/11072449
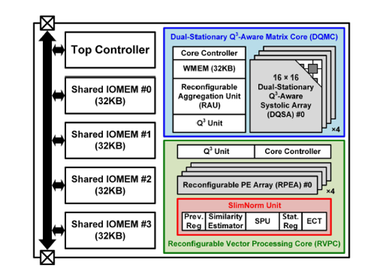
Summary: This brief presents a novel data-format-based image deblurring accelerator with layer normalization and UNet architecture optimization for mobile cameras. The proposed accelerator enables energy-efficient acceleration of deblurring through the following three key features: 1) A Quad-base-Quad-scale Quantized format that maintains image quality with only 8-bit, reducing external memory access (EMA) by 33% and achieving 75.7% higher multiply-and-accumulation (MAC) energy efficiency compared to conventional 12-bit precision; 2) A Layer Normalization-Aware Optimization technique, enabling parallel normalization and fusion of affine transformation; 3) A dual-stationary systolic array architecture that selects the optimal dataflow for each UNet block based on processing element (PE) utilization. As a result, the proposed accelerator achieves 2.49 TOPS/W, which is 2.23× higher than prior work, enabling energy-efficient deblurring for mobile applcations.
Paper 3:
P. Kmon, R. Kleczek, R. Szczygiel, G. Wegrzyn, “SPECTRUM1k – 75 μm Pixels Pitch IC With In-Pixel Histogramming for X-Ray Color Imaging,” IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 72, no. 8, pp. 1003 - 1007, Aug. 2025. doi: 10.1109/TCSII.2025.3579856 https://ieeexplore.ieee.org/document/11046196
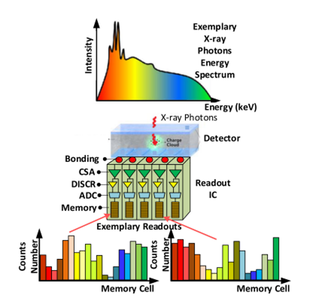
Summary: A new single photon-counting IC prototype called SPECTRUM1k with pixel matrix 40×24 and pixel pitch 75 μ m is developed by the Microelectronics Group of the AGH University of Krakow as a solution for X-ray color imaging. The chip, produced in CMOS 40nm technology, is made up of 960 individually configured pixels, each composed of an amplifier, an analog-to-digital converter, and 64×12 -bit memory cells that allow one to perform in-pixel energy histogramming. Thanks to the proposed architecture working with the 200 MHz chip clock and 1 Gcps/mm2 multi energy photon intensities up-to about 23 ms exposition time is feasible ( 365 μ s exposition time whenever monoenergetic photons are used only).
IEEE Transactions on Circuits and Systems for Video Technologies
Paper 1:
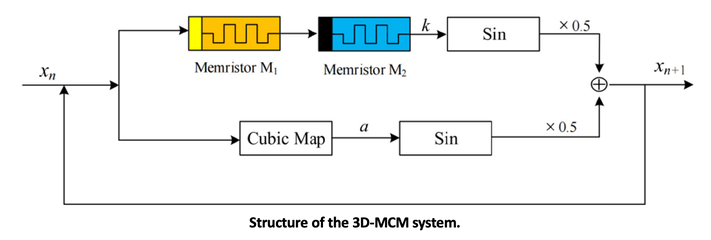
H. Ho-Ching Iu, U. Erkan, C. Simsek, A. Toktas, Y. Cao, "A 3D Memristive Cubic Map With Dual Discrete Memristors: Design, Implementation, and Application in Image Encryption," IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 8, pp. 7706-7718, Aug. 2025, doi: 10.1109/TCSVT.2025.3545868.
This paper introduces a novel discrete chaotic system employing dual memristors, named the 3D memristive cubic map with dual discrete memristors (3D-MCM). The 3D-MCM system demonstrates richer and more intricate dynamical behaviors compared to its single-memristor counterparts, as verified through bifurcation diagrams, Lyapunov exponent spectra, and complexity analyses. Notably, the system exhibits coexisting attractors, substantially enhancing its dynamical complexity. Hardware implementation of the 3D-MCM attractors confirms its feasibility for industrial applications. To illustrate the system potential in encryption tasks, this study integrates the quaternary-based permutation and dynamic emanating diffusion (QPDED-IE) scheme with the 3D-MCM for image encryption. Experimental results demonstrate that the QPDED-IE scheme based on the 3D-MCM exhibits strong diffusion and confusion properties, effectively resisting cryptanalytic attacks
Paper 2:
X. Min, Y. Gao, Y. Cao, G. Zhai, W. Zhang, H. Sun, "Exploring Rich Subjective Quality Information for Image Quality Assessment in the Wild," in IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 8, pp. 7778-7791, Aug. 2025, doi: 10.1109/TCSVT.2025.3544659.
This paper propose a novel Image Quality Assessment (IQA) method named RichIQA to explore the rich subjective rating information beyond MOS to predict image quality in the wild. RichIQA is characterized by two novel designs: 1) a three-stage image quality prediction network, which exploits the powerful feature representation capability of the Convolutional vision Transformer (CvT) and mimics the short-term and long-term memory mechanisms of human brain; 2) a multi-label training strategy in which rich subjective quality information like MOS, SOS and DOS are concurrently used to train the quality prediction network. Powered by these two novel designs, RichIQA is able to predict the image quality in terms of a distribution, from which the mean image quality can be subsequently obtained. Experimental results verify that the three-stage network is tailored to predict rich quality information, while the multi-label training strategy can fully exploit the potentials within subjective quality rating and enhance the prediction performance and generalizability of the network. It is also shown RichIQA outperforms state-of-the-art competitors on multiple large-scale in the wild IQA databases with rich subjective rating labels
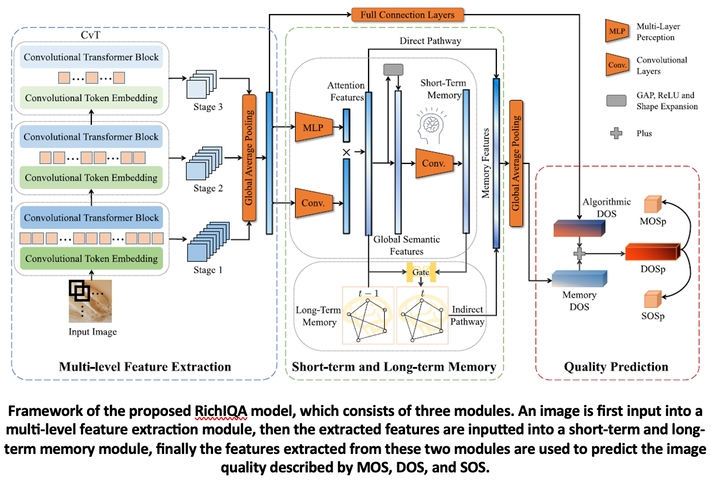
Paper 3:
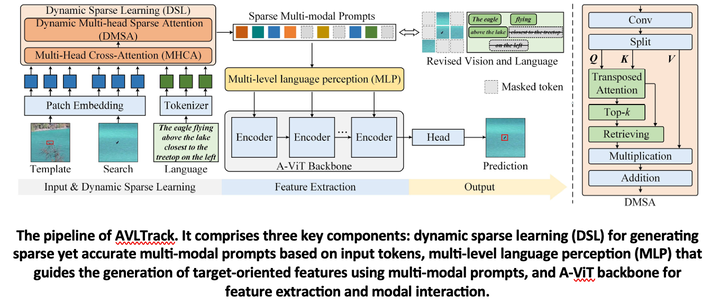
Y. Xue, B. Zhong, G. Jin, T. Shen, L. Tan, N. Li, "AVLTrack: Dynamic Sparse Learning for Aerial Vision-Language Tracking," in IEEE Transactions on Circuits and Systems for Video Technology, vol. 35, no. 8, pp. 7554-7567, Aug. 2025, doi: 10.1109/TCSVT.2025.3549953.
This work presents a flexible framework for aerial vision-language tracking called AVLTrack. It consists of three key components, a dynamic sparse learning (DSL) module, an efficient Transformer backbone, and a multi-level language perception (MLP) strategy. First, DSL sparsely connects language and images via dynamic sparse attention, providing accurate multi-modal prompts. To adapt to target state variations, the sparsity in DSL is dynamically adjusted based on semantic information, flexibly highlighting target-specific tokens. Next, the Transformer backbone follows highly parallelized one-stream architectures, allowing efficient multi-modal feature extraction and interaction. Finally, MLP enables the iterative interaction of language and visual information, aiming to utilize language priori to guide the generation of discriminative visual features. As an additional contribution of this work, the DTB70-NLP dataset is collected to facilitate UAV vision-language tracking. Experiments on WebUAV-3M and DTB70-NLP demonstrate the effective performance of AVLTrack compared to existing trackers, while maintaining a high running speed of 80.5 FPS. The dataset and codes are available at https://github.com/xyl-507/AVLTrack
IEEE Transactions on Very Large Scale Integration (VLSI) Systems
Paper 1:
Das, S., Riedel, S., Naeim, M., Brunion, M., Bertuletti, M., Benini, L., Ryckaert, J., Myers, J., Biswas, D. and Milojevic, D., 2024. "Bandwidth-Latency-Thermal Co-Optimization of Interconnect-Dominated Many-Core 3D-IC," IEEE Transactions on Very Large Scale Integration (VLSI) Systems. vol. 33, no. 2, pp. 346-357, Feb. 2025, doi: 10.1109/TVLSI.2024.3467148 https://ieeexplore.ieee.org/document/10720515
Summary: The article addresses the challenges faced by contemporary system-on-chips (SoCs) due to the increasing demands for memory bandwidth, capacity, and thermal stability, particularly in the context of advancing artificial intelligence (AI). It proposes architectural modifications for a many-core SoC designed to enhance on-chip cache memory bandwidth and optimize access latency. The SoC is fabricated using A10 nanosheet technology in a 3-D configuration, with thermal analyses conducted. Workload simulations demonstrate significant performance improvements, achieving up to 12-fold acceleration for a 64-core version and 2.5-fold for a 16-core version, accompanied by a 40% increase in die area and a 60% rise in power dissipation when using a 2-D design. In comparison, the 3-D design not only minimizes the physical footprint but also saves 20% in power consumption due to a 40% reduction in wirelength. The study emphasizes the importance of restructuring pipelines to optimize the benefits of 3-D technology for enhanced memory access and lower latency. Additionally, it explores thermal impacts of different 3-D partitioning approaches in high-performance computing (HPC) and mobile applications, finding that 3-D designs in mobile contexts only slightly increase maximum temperature (by about 2-3 °C) compared to 2-D, while HPC scenarios require careful partitioning strategies to effectively manage thermal constraints.
Paper 2:
G. Murali, M. Gyu Park and S. Kyu Lim, "3DNN-Xplorer: A Machine Learning Framework for Design Space Exploration of Heterogeneous 3-D DNN Accelerators," IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 33, no. 2, pp. 358-370, Feb. 2025, doi: 10.1109/TVLSI.2024.3471496. https://ieeexplore.ieee.org/document/10715720
Summary: This paper introduces 3DNN-Xplorer, a novel machine learning (ML)-based framework for predicting the performance of heterogeneous 3-D deep neural network (DNN) accelerators. This framework enables design space exploration (DSE) of these accelerators with a two-tier compute-on-memory (CoM) configuration, considering 3-D physical design factors. The framework explores four distinct heterogeneous 3-D integration styles combining 28-nm and 16-nm technology nodes for both compute and memory tiers. Through extrapolation techniques and ML models trained on various accelerator configurations, the performance of larger systems is estimated, achieving a maximum absolute error of 13.9%. The framework considers area imbalance arising from different technology nodes by assuming equal numbers of PEs or on-chip memory capacity across integration styles. The analysis reveals that the heterogeneous 3-D style with 28-nm compute and 16-nm memory demonstrates energy-efficient performance, offering up to 50% energy savings and an 8.8% reduction in runtime compared to other 3-D integration styles. Conversely, the heterogeneous 3-D style with 16-nm compute and 28-nm memory proves area-efficient, exhibiting up to 8.3% runtime reduction compared to other 3-D styles.
Paper 3:
A. Almeida da Silva, L. Nogueira, A. Coelho, J. A. N. Silveira and C. Marcon, "Securet3d: An Adaptive, Secure, and Fault-Tolerant Aware Routing Algorithm for Vertically–Partially Connected 3D-NoC," IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 33, no. 1, pp. 275-287, Jan. 2025, doi: 10.1109/TVLSI.2024.3500575 https://ieeexplore.ieee.org/document/10766899
Summary: This article presents Securet3d, a novel routing algorithm designed for multiprocessor systems-on-chip (MPSoCs) that utilize 3-D networks-on-chip (3D-NoCs), aimed at enhancing secure and fault-tolerant operations. As MPSoCs play a crucial role in achieving effective parallel computing by sharing resources across complex applications, implementing adaptive mechanisms to safeguard sensitive data is essential. Securet3d builds upon the existing Reflect3d algorithm, introducing a comprehensive mapping scheme for secure data pathways and improving the system’s fault tolerance. The algorithm's effectiveness is validated through comparisons with three other fault-tolerant routing algorithms in vertically-partially connected 3D-NoCs. All algorithms were developed in SystemVerilog and evaluated via simulations using ModelSim, and hardware synthesis was performed with Cadence’s Genus tool. The experimental results indicate that Securet3d not only reduces latency but also enhances cost-effectiveness compared to other methods. Implemented with a 28-nm technology library, Securet3d exhibits minimal area and energy overhead, demonstrating its scalability and efficiency. Moreover, during denial-of-service (DoS) attacks, Securet3d maintains relatively stable average packet latencies of 70, 90, and 29 clock cycles for uniform random, bit-complement, and shuffle traffic, respectively, which are significantly lower than the latencies observed in other algorithms lacking security mechanisms (5763, 4632, and 3712 clock cycles on average). These findings underscore Securet3d's superior security, scalability, and adaptability for complex communication systems.
IEEE Journal on Emerging and Selected Topics in Circuits and Systems
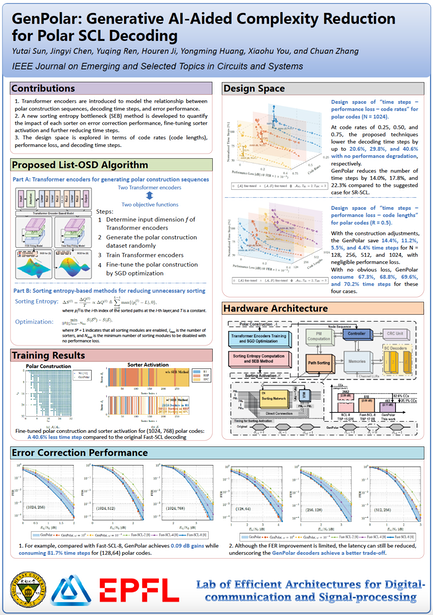
Paper 1:
Y. Sun et al., "GenPolar: Generative AI-Aided Complexity Reduction for Polar SCL Decoding," in IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 15, no. 2, pp. 312-324, June 2025, doi: 10.1109/JETCAS.2025.3561330.
[It's open access!]
Summary: As 6G technologies advance, the high complexity of successive cancellation list (SCL) decoding for polar codes becomes a critical hurdle, while existing complexity reduction strategies suffer from limitations; generative AI (GenAI) technologies like Transformer models offer new potential to address these issues by modeling complex relationships in encoding and decoding processes. This paper proposes GenPolar, a hardware-friendly and GenAI-aided approach involving two-step optimization: Transformer encoders for generating polar construction sequences and a sorting entropy-based method for reducing unnecessary sorting operations. For polar codes of length-1024 with code rates of 0.25, 0.50, and 0.75, GenPolar achieves latency reductions of 20.6%, 29.8%, and 40.6% respectively, with negligible performance loss, and outperforms the reduced-complexity version of Fast-SCL decoding by 14.0%, 17.8%, and 22.3%
Paper 2:
G. Zhang, D. Zou, K. Sun, Z. Chen, M. Wang and Z. Wang, "GEMMV: An LLM-Based Automated Performance-Aware Framework for GEMM Verilog Generation," in IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 15, no. 2, pp. 325-336, June 2025, doi: 10.1109/JETCAS.2025.3568712.
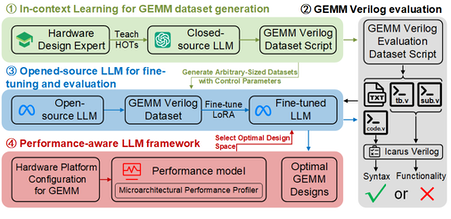
Summary: As a major performance and energy bottleneck in AI accelerators, General Matrix Multiplication (GEMM) design is time-consuming and expertise-intensive, making LLMs highly promising for automating GEMM hardware design. However, lack of specialized hardware datasets and the absence of performance awareness in LLMs render existing LLM-based RTL generation methods inadequate for GEMM hardware design. This study proposes GEMMV, a performance-aware LLM-based framework that automatically generates optimized GEMM hardware designs. It introduces the first automated approach for creating a well-annotated Verilog dataset across GEMM variants and integrates performance models spanning from the microarchitecture to the system level into fine-tuned LLMs to enable performance awareness. Compared to prior work, GEMMV improves syntax correctness by 65% and functional correctness by 70%, while the GEMM modules generated by GEMMV achieve a 3.1× reduction in latency.
Paper 3:
J. Ryu and H. -J. Yoo, "An Overview of Neural Rendering Accelerators: Challenges, Trends, and Future Directions," in IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 15, no. 2, pp. 299-311, June 2025, doi: 10.1109/JETCAS.2025.3561777. [It's open access!]
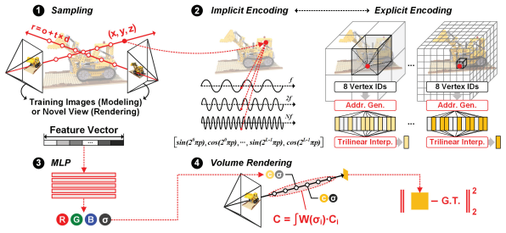
Summary: Rapid advancements in neural rendering have revolutionized the fields of augmented reality (AR) and virtual reality (VR) by enabling photorealistic 3D modeling and rendering. However, deploying neural rendering on edge devices presents significant challenges due to computational complexity, memory inefficiencies, and energy constraints. This paper provides a comprehensive overview of neural rendering accelerators, identifying the major hardware inefficiencies across sampling, positional encoding, and multi-layer perception (MLP) stages. We explore hardware-software co-optimization techniques that address these challenges and provide a summary for in-depth analysis. Additionally, emerging trends like 3D Gaussian Splatting (3DGS) and hybrid rendering approaches are briefly introduced, highlighting their potential to improve rendering quality and efficiency. By presenting a unified analysis of challenges, solutions, and future directions, this work aims to guide the development of next-generation neural rendering accelerators, especially for resource-constrained environments
IEEE Open Journal of Circuits and Systems
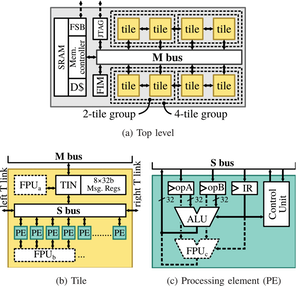
Paper 1:
T. Kaiser, E. Gottschalk, K. Biethahn and F. Gerfers, "Pasithea-1: An Energy-Efficient Sequential Reconfigurable Array With CPU-Like Programmability," IEEE Open Journal of Circuits and Systems, vol. 6, pp. 1-13, 2025, doi: 10.1109/OJCAS.2024.3518110. https://ieeexplore.ieee.org/document/10802954
Summary: This work presents Pasithea-1, a coarse-grained reconfigurable array (CGRA) that combines energy efficiency with CPU-like programmability.
Paper 2:
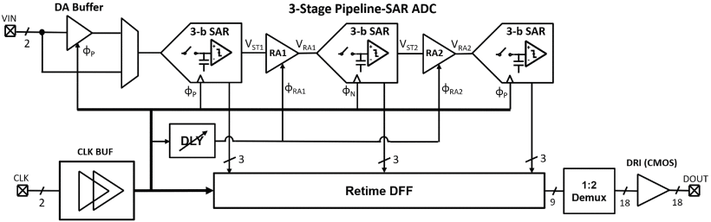
B. Yang, T. Caldwell and A. Chan Carusone, "An Energy-Efficient Pipeline-SAR ADC Using Linearized Dynamic Amplifiers and Input Buffer in 22nm FDSOI," IEEE Open Journal of Circuits and Systems, vol. 6, pp. 50-62, 2025, doi: 10.1109/OJCAS.2024.3509746. https://ieeexplore.ieee.org/document/10774063
Summary: This work presents a dynamic amplifier that achieves −52 dB in total harmonic distortion through an analog technique by which the expanding and compressing nonlinearities in the input transistors cancel one another. A pipeline-SAR analog-to-digital converter incorporating the linearized dynamic amplifier in both the input buffer and the first residue amplifier stage was designed and fabricated using the GlobalFoundries 22nm fully depleted silicon-on-insulator process.
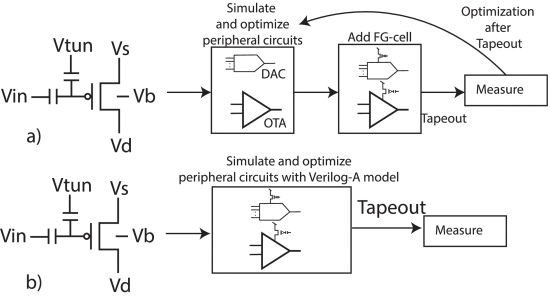
Paper 3:
S. Nowshin Chowdhury, M. Chen and S. Shah, "Analysis and Verilog-A Modeling of Floating-Gate Transistors," IEEE Open Journal of Circuits and Systems, vol. 6, pp. 63-73, 2025, doi: 10.1109/OJCAS.2024.3524363. https://ieeexplore.ieee.org/document/10818976
Summary: This work presents a Verilog-A model based on empirical measurements for a floating-gate transistor fabricated using a 65 nm CMOS process.
________________
IEEE CAS Magazine Third Quarter Issue 2025

Now available: Third Quarter Issue
IEEE Circuits and Systems (CAS) Magazine publishes original review articles and other articles that are of broad interest to the Circuits and Systems Society community. Interested authors are invited to send a three to four page White Paper first to the Editor-in-Chief, Prof. Keshab K. Parhi, by email here. If invited, they can submit a Full Paper at the Author Portal at the link below. CAS Magazine will continue to publish articles related to CAS Society Outreach. In addition, CAS Magazine also publishes articles related to education (such as tricks in solving problems and short lecture notes), conference highlights, chapter highlights, applications, and standards. Please feel free to submit articles that are of broad interest to the members of the CAS Society. For more information, please visit the IEEE Circuits and Systems Magazine on the CASS website.
________________
Active "Call for Papers” Archive

______________________________
Latest Tables of Contents of CAS Sponsored Journals
The latest issues of our CAS sponored journals have been published and the tables of contents can be accessed through the following links:

- IEEE Transactions on Circuits and Systems I: Regular Papers
- IEEE Transactions on Circuits and Systems II: Express Briefs
- IEEE Transactions on Circuits and Systems for Video Technology
- IEEE Journal on Emerging and Selected Topics in Circuits and Systems
- IEEE Circuits and Systems Magazine
- IEEE Transactions on Biomedical Circuits and Systems
- IEEE Design and Test Magaz