Our Editors-in-Chief’s Top Picks
The Editors-in-Chief of our CASS publications have selected some noteworthy papers from the recent issues of our journals:
IEEE Transactions on Circuits and Systems I: Regular Papers
Paper 1
Z. Gu, Y. Zhang, Y. Zhao, J. Zhang, Y. Zeng, Z. Luo, and Y. Li, "Synthesizing Step-Down Switched Capacitor Power Converter Topologies," IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 71, no. 3, pp. 1465-1479, March 2024, doi: 10.1109/TCSI.2023.3336718.https://ieeexplore.ieee.org/abstract/document/10339894
Summary: Switched capacitor (SC) DC-DC converters are preferred in low-power wearable and implantable devices because they can be fully integrated on-chip. As an SC converter topology only provides a discrete conversion ratio, numerous converter topologies have been explored based on canonical forms or general network models. However, a canonical form limits the optimum performance, while a general network model requires a prohibitive amount of computation. This work proposes a step-down SC converter synthesis framework that generates optimum converter topologies under the design constraints of the conversion ratio and a minimum number of capacitors. The proposed rule-based clustering techniques significantly reduced computational tasks and runtime. For example, in 4:1 converter synthesis, the conversion ratio analysis task and the total runtime are reduced by 34767x and 11353x. The framework optimizes the wiring connection of cascaded 2:1 topology and Fibonacci topology, resulting in 4.7% and 12.8% peak efficiency improvement. The framework also identifies topology variants for cascaded 2:1 topology with 8.2% peak efficiency improvement. In addition, the framework unveils new topologies whose performance is comparable with existing optimum topologies.
Paper 2:
C. Grimm, J. Lee, and N. Verma, "Training Neural Networks With In-Memory-Computing Hardware and Multi-Level Radix-4 Inputs," IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 71, no. 4, pp. 1781-1793, April 2024, doi: 10.1109/TCSI.2024.3360052. https://ieeexplore.ieee.org/document/10431596
Summary: Training Deep Neural Networks (DNNs) takes an immense number of operations and therefore a lot of computational power. While numerous accelerators exist to reduce the power consumption for running pre-trained DNNs (inference), training proves to be a more challenging task. Two reasons for this are that training requires higher precision computations and computations over much more data than inferencing. In-Memory Computing (IMC) is an approach that can overcome the challenges of managing large amounts of data, but to do so it leverages analog computations for energy and area efficiency, which limits its achievable precision. In this paper, we explore and test novel training methods capable of obtaining high performance on DNN accelerators with significant levels of analog noise. We demonstrate the possibility of using IMC for training DNNs within 2% of performances obtained by GPUs at 3 orders of magnitude greater energy efficiency.
Paper 3
C. Liu, W. Wang, B. Jiang, and R. J. Patton, "Fault-Tolerant Consensus of Multi-Agent Systems Subject to Multiple Faults and Random Attacks," IEEE Transactions on Circuits and Systems I: Regular Papers, doi: 10.1109/TCSI.2024.3351214. https://ieeexplore.ieee.org/document/10416799
Summary: The propagation of both physical faults and cyber-attack information among agents can lead to degradation or failure of consensus tasks in multi-agent systems. Hence, designing appropriate fault-tolerant consensus control (FTCC) algorithms is necessary. However, single fault-tolerant or anti-attack resilient control algorithms cannot effectively address the complexity of multiple physical faults, channel noises, nonlinear factors, and random cyber-attacks simultaneously. Furthermore, achieving expected consensus objectives while balancing computational complexity and efficiency improvements in the face of complex cyber-physical threats is highly challenging. In this talk, FTCC techniques based on a double-layer distributed strategy developed to address these challenges are introduced.
Paper 4
F. Guella, E. Valpreda, M. Caon, G. Masera, and M. Martina, "MARLIN: A Co-Design Methodology for Approximate ReconfigurabLe Inference of Neural Networks at the Edge," IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 71, no. 5, pp. 2105-2118, May 2024, doi: 10.1109/TCSI.2024.3365952. https://ieeexplore.ieee.org/abstract/document/10449675
Summary: Deploying neural networks (NNs) on edge devices is challenging due to the high energy consumption. A possible solution is to reduce the cost of multiplication, the core operation in NNs, with approximate multipliers, trading off energy with accuracy. However, it is necessary to search which layers can be approximated and to which degree, as they have different error robustness. The MARLIN framework is designed to take an exact NN and select the multiplier's approximation level for each layer, balancing energy and accuracy. Finally, it automates the deployment on a RISC-V-based microcontroller, embedding approximation control in the code.
Paper 5
P. Kumar, A. Nandi, A. Saha, K. S. P. Teja, R. Das, S. Chakrabartty, and C. S. Thakur, "ARYABHAT: A Digital-Like Field Programmable Analog Computing Array for Edge AI," IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 71, no. 5, pp. 2252-2265, May 2024, doi: 10.1109/TCSI.2024.3349776. https://ieeexplore.ieee.org/abstract/document/10391073
Summary: ARYABHAT is a unique chipset designed specifically for Edge AI applications. It features scalable current-mode Margin-propagation (MP) circuits that are robust to PVT variations, allowing the analog computing architecture to be field-programmable for throughput and power-dissipation, just like digital FPGAs. This work includes notable contributions such as MP-based near-memory crossbar computational tile, a digital-like analog synthesis flow, as well as the development of the ARYAFlow mapper and ARYATest framework for hardware-algorithm co-design, testing, and verification. Demonstrations showcase the versatility of ARYABHAT's field-programmable capabilities in various applications, including neural networks, support vector machines, and signal filtering.
IEEE Transactions on Circuits and Systems II: Express Briefs
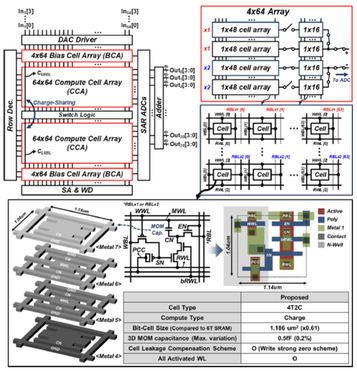
Paper 1
In-Jun Jung, Do Han Kim, Minyoung Jo, Dong Han Ko, Youngkyu Lee, Seong-Ook Jung, “A Charge-Domain 4T2C eDRAM Compute-in-Memory Macro With Enhanced Variation Tolerance and Low-Overhead Data Conversion Schemes”, IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 71, no. 4, pp. 1824 – 1828, Apr. 2024. doi: 10.1109/TCSII.2023.3332749. https://ieeexplore.ieee.org/document/10318198
Summary: In this brief, a charge-domain 4T2C eDRAM-CIM macro is proposed with a 4T2C eDRAM cell and enhanced PVT variation tolerance. A quarter-ADC-reduction scheme with an offset-calibration comparator that reduces the number of ADC by 73% while improving the accuracy drop by 7.82%, and an array-embedded DAC that reduces the area overhead
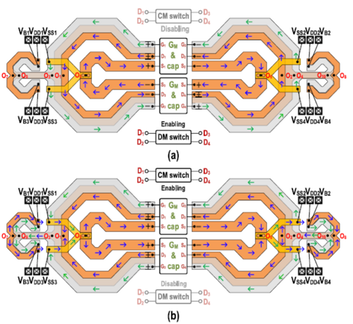
Paper 2:
Ya Zhao, Chao Fan, Yuanxing Peng, Chenglong Liang, Jun Yin, Pui-In Mak, Li Geng, “A 12.9-to-24 GHz Dual-Mode Multi-Coil VCO Achieving 199.2 dBc/Hz Peak FoMT in 65-nm CMOS”, IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 71, no. 5, pp. 2604 - 2608, May. 2024. doi: 10.1109/TCSII.2024.3350678. https://ieeexplore.ieee.org/document/10382575
Summary: This paper reports a mode-switching dual-core multi-coil voltage-controlled oscillator (VCO) with improved frequency tuning range (FTR) and phase noise (PN). Specifically, the VCO utilizes the head transformer (HT) and source center-tap inductor to enable dual-mode operation for FTR extension.
Paper 3:
Sanghyuk An, Junha Ryu, Gwangtae Park, Hoi-Jun Yoo, “A 8.81 TFLOPS/W Deep-Reinforcement-Learning Accelerator With Delta-Based Weight Sharing and Block-Mantissa Reconfigurable PE Array”, IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 71, no. 5, pp. 2529 - 2533, May. 2024. doi: 10.1109/TCSII.2024.3374725. https://ieeexplore.ieee.org/document/10268969
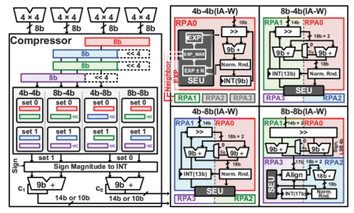
Summary: This paper proposes a Deep Reinforcement Learning accelerator with a Delta-based Weight Sharing (DWS) represents weights by referencing corresponding network and exploits data locality, and a Block-Mantissa Reconfigurable PE Array (BMRPA) supports variable operations in blocks and mantissa to provide optimal precision for each layer, resulting in up to a 4× increase in throughput. Also, a Multi-mode Data Fetcher (MDF) supports bit width adaptive data fetching, achieving twice the bandwidth with an average read overhead of 5.3%. The overall implementation attains an energy efficiency of 8.81 TFLOPS/W.
IEEE Journal of Emerging and Selected Topics in Circuits and Systems
Paper 1
C. Wang, P. -C. Chiu, C. -L. Ko, S. -H. Tseng and C. -H. Li, "A 340-GHz THz Amplifier-Frequency-Multiplier Chain With 360° Phase-Shifting Range and its Phase Characterization," IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 14, no. 1, pp. 52-66, March 2024, doi: 10.1109/JETCAS.2023.3345358. https://ieeexplore.ieee.org/document/10367994
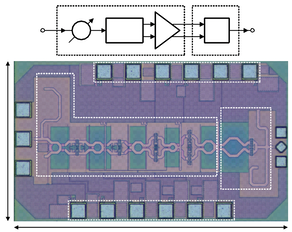
Summary: In this paper, the authors show a THz compact amplifier-frequency-multiplier chain (AMC) offering a full 360° phase shifting range for 6G phased-array applications and a measurement setup for characterizing the phase of a THz signal. The novel AMC comprises an 85-GHz phase-shifter-embedded (Δφ-embedded) power amplifier (PA) simultaneously supporting power amplification and phase-shifting functions and a high-output-power 340-GHz frequency quadrupler (FQ) incorporating an optimal output harmonic impedance matching network (IMN). Implemented in a 40-nm CMOS technology without ultra-thick metal layers available, the THz AMC achieves an output power of –4.4 dBm and a conversion gain of 0.7 dB at 324 GHz while providing a tunable output phase over 360° within the 324 to 346 GHz frequency range.
Paper 2
W.-C. Chen and H. -Y. Chang, "Design and Analysis of a V-Band CMOS Sextuple SILVCO Using Transformer and Cascade-Series Coupling With a Frequency-Tracking Loop," IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 14, no. 1, pp. 75-87, March 2024, doi: 10.1109/JETCAS.2023.3329430. https://ieeexplore.ieee.org/document/10304163
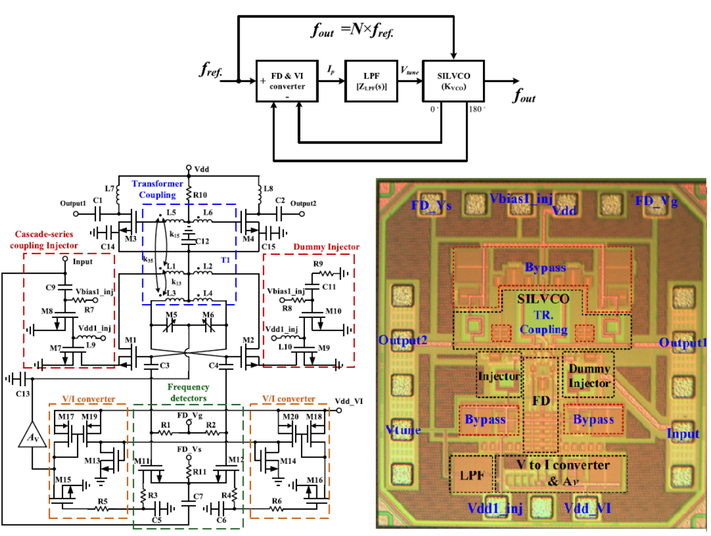
Summary: A low-phase-noise local oscillator (LO) is a crucial component in communication systems. However, the design challenge of the LO significantly increases as the operating frequency rises. This paper focuses on the design and analysis of a V-band CMOS sextuple sub-harmonically injection-locked voltage-controlled oscillator (SILVCO) with a frequency-tracking loop (FTL). The SILVCO with FTL is implemented using a 90-nm CMOS process. With a sub-harmonic number of 6 and a DC power consumption of 23 mW, the measured output frequency ranges from 50.8 to 53.4 GHz, achieving a differential output power close to 0 dBm. The measured phase noise at a 1 MHz offset and the rms jitter integrated from 1 kHz to 10 MHz are both lower than -109.4 dBc/Hz and 43 fs, respectively
Paper 3
L. Chen, L. Chen, D. Sun, Y. Sun, Y. Pan and X. Zhu, "A 39 GHz Doherty-Like Power Amplifier With 22dBm Output Power and 21% Power-Added Efficiency at 6dB Power Back-Off," IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 14, no. 1, pp. 88-99, March 2024, doi: 10.1109/JETCAS.2024.3351075. https://ieeexplore.ieee.org/document/10382503
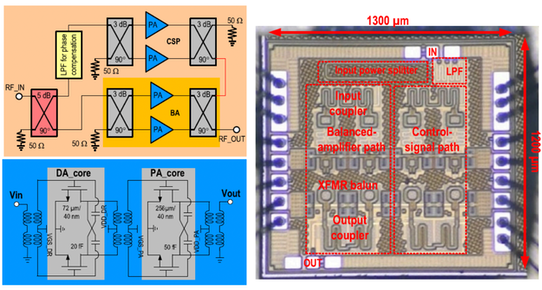
Summary: The design of a Doherty-like power amplifier for millimetre-wave (mm-wave) applications is presented in this work. The designed power amplifier employs a novel symmetrical load-modulated balanced amplifier (S-LMBA) architecture. The S-LMBA is fabricated in a 45-nm CMOS SOI technology. At 39 GHz, a 22.1 dBm saturated output power with a maximum power-added efficiency (PAE) of 25.7% is achieved. An average output power of 13.1 dBm with a PAE of 14.4% at an error vector magnitude above -22.5 dB and adjacent channel power ratio of -23 dBc is also achieved, when a 200 MHz single carrier 64-quadrature-amplitude-modulation signal is used. Including all testing pads, the footprint of the designed S-LMBA is only 1.56 mm2.
IEEE Transactions on Circuits and Systems for Video Technology
Paper 1
Changshuo Wang, Xin Ning, Weijun Li, Xiao Bai, and Xingyu Gao. “3D Person Re-Identification Based on Global Semantic Guidance and Local Feature Aggregation,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 6, June 2024. https://ieeexplore.ieee.org/document/10301577
Summary: Most existing person re-identification (Re-ID) methods learn pedestrian feature representations from images, so ignoring the real 3D human body structure and the spatial relationship between the pedestrians and interferents. To address these limitations in the current literature of person Re-ID, this paper proposes a new point cloud Re-ID network, named PointReIDNet, designed to obtain 3D shape representations of pedestrians from point clouds of 3D scenes. The model consists of two modules: a global semantic guidance module and a local feature extraction module. The global semantic guidance module is designed to enhance the point cloud feature representation in similar feature neighborhoods and to reduce the interference caused by 3D shape reconstruction or noise. A space cover convolution (SC-Conv) is also proposed to efficiently represent point clouds by encoding information on human shapes in local point clouds. Results obtained on four holistic person Re-ID datasets, one occlusion person Re-ID dataset and one point cloud classification dataset exhibit significant improvements over point-cloud based person Re-ID methods.
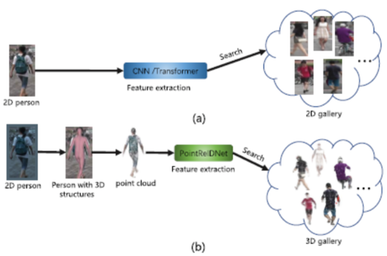
Figure (right): (a) A general person re-identification method based on 2D images; (b) The method proposed in this paper to learn pedestrian features from a 3D space.
Paper 2:
Jun Tang, Chenyan Lu, Zhengxue Liu, Jiale Li, Hang Dai, and Yong Ding. "CTVSR: Collaborative Spatial–Temporal Transformer for Video Super-Resolution,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 6, June 2024. https://ieeexplore.ieee.org/document/10347267
Summary: This paper proposes a Collaborative Transformer for Video Super-Resolution (CTVSR). The proposed method integrates the strengths of Transformer-based and recurrent-based models by concurrently assimilating the spatial information derived from multi-scale receptive fields and the temporal information acquired from temporal trajectories. In particular, a Spatial Enhanced Network (SEN) is proposed with two key components: Token Dropout Attention (TDA) and Deformable Multi-head Cross Attention (DMCA). TDA focuses on the key regions to extract more informative features, and DMCA employs deformable cross attention to gather information from adjacent frames. A Temporal-trajectory Enhanced Network (TEN) is also introduced that computes the similarity of a given token with temporally related tokens in the temporal trajectory. Experiments on four widely used VSR benchmarks, show the CTVSR method proposed in this paper is capable of achieving competitive performance with relatively low computational consumption and high forward speed.
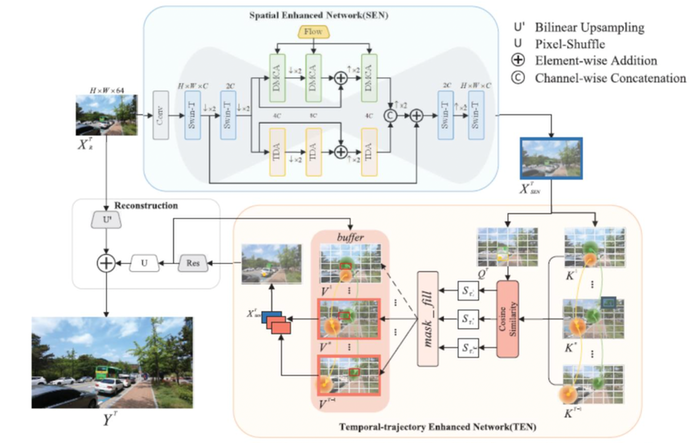
Figure (above): Overview of the Collaborative Transformer for Video Super-Resolution (CTVSR) approach proposed in this paper. The Spatial Enhanced Network (SEN) leverages Token Dropout Attention (TDA) and Deformable Multi-head Cross Attention (DMCA) to integrate local details and global information and thus derive spatial features. Inside the TEN module, two temporal trajectories are visualized using green color and orange color, respectively. The size of those circles in TEN represents the search range of the colored tokens. Then, analysis is conducted on the green token; the orange token indicates the useful search range is distinct for every token across time. Flow is produced by a pre-trained optical flow estimation model (SpyNet). Res(·) stacks several residual blocks to reconstruct details.
Paper 3:
Min Cao, Yang Bai, Ziqiang Cao, Liqiang Nie, and Min Zhang. "Efficient Image-Text Retrieval via Keyword-Guided Pre-Screening,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 6, June 2024. https://ieeexplore.ieee.org/document/10342878
Summary: This paper proposes a simple and effective keyword-guided pre-screening framework for image-text retrieval. The image and text data are converted into keywords and keyword matching is performed across the modalities to exclude a large number of irrelevant gallery samples prior to the retrieval network. The keyword prediction is transferred into a multi-label classification problem and a multi-task learning scheme is proposed by appending the multi-label classifiers to the image-text retrieval network. This aims to obtain a lightweight and high-performance keyword prediction. For keyword matching, the inverted index from the search engine is introduces and thus a win-win situation is created on both time and space complexities for the pre-screening. Experiments on the Flickr30K and MS-COCO, verify the effectiveness of the proposed framework: with only two embedding layers it achieves O(1) querying time complexity, while improving the retrieval efficiency and maintaining performance, when applied prior to common image-text retrieval methods.
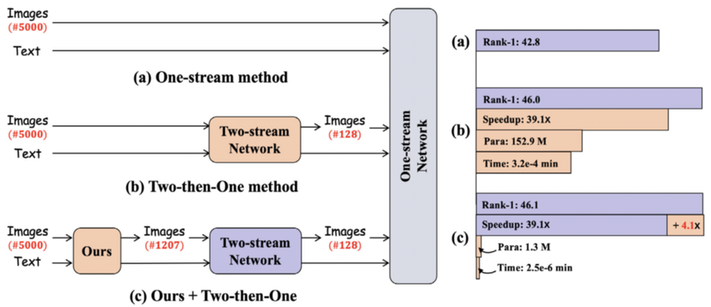
Figure (above): On the left the skeleton of various image-text retrieval methods is shown for the example case of text-to-image retrieval. On the right, the methods on the left are compared. Rank-1 denotes the expectation of correct match at the 1st in the ranking list (performance index) and Speedup refers to the retrieval acceleration from the acceleration module (efficiency index). Time and Para represent the online running time and the number of parameters of the acceleration module, respectively. These results are computed based on the one-stream network ViLT and two-stream network ALBEF0 on MS-COCO. In the framework proposed in this paper, the classification by multi-task learning on the ALBEF is proposed.
IEEE Transactions on Biomedical Circuits and Systems
Paper 1
Löhler P, Albert A, Erbslöh A, Müller F, Seidl K. A cell-type selective stimulation and recording system for retinal ganglion cells. IEEE Transactions on Biomedical Circuits and Systems. 2023 Dec 14. https://ieeexplore.ieee.org/document/10360310/
Summery: This paper is focusing on the development of a cell-type selective stimulation and recording system targeting Retinal Ganglion Cells (RGCs) for future retinal implants. The system aims to provide patients with more natural visual perceptions by selectively activating different RGC sub-types. The authors, Philipp Löhler et al., have created a 42-channel system-on-chip (SoC) capable of stimulating retinal tissue with sinusoidal frequencies above 1 kHz and amplitudes up to 200 µA. The SoC features a camera-based input system that processes images in real-time to determine the appropriate stimulation parameters for selective RGC activation. The system uses a Difference of Gaussian (DoG) algorithm implemented on a field-programmable gate array (FPGA) to mimic the behavior of retinal neurons and convert light into electrical stimulation parameters. The stimulation pipeline includes a real-time target RGC selection algorithm, which is crucial for the system's closed-loop functionality. The authors have also designed a recording unit integrated into each stimulation cluster to detect evoked extracellular action potentials. This unit includes tunable recording units with an action potential detection pipeline, capable of amplifying signals between 1 Hz and 50 kHz. The system's functionality was validated using in vitro experiments, showing that the novel sinusoidal stimulation approach more closely mimics natural light responses of RGCs compared to conventional rectangular stimulation.
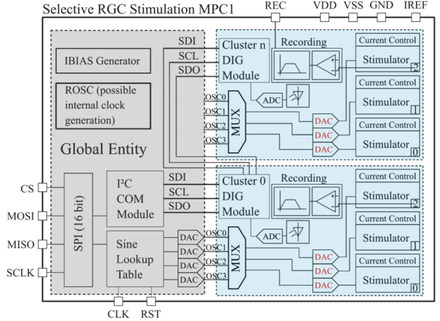
Fig.5. Modular Block diagram depicting thr globally available modules (grey) and two of the 14 cluster entities (blue) for reasons of clarity. Each cluster includes three stimulation channels and one recording unit. Waveform gener- ation DACs are marked in black, amplitude modulation DACs in red. Internal communication is managed by an I 2 C bus while external communications are handled by an SPI interface.
Paper 2
Carlino MF, Gielen G. Brain Feature Extraction with an Artifact-Tolerant Multiplexed Time-Encoding Neural Frontend for True Real-Time Closed-Loop Neuromodulation. IEEE Transactions on Biomedical Circuits and Systems. 2023 Dec 20. https://ieeexplore.ieee.org/document/10366816/
Summary: This article presents a novel neural readout frontend designed to enable real-time closed-loop neuromodulation by effectively handling stimulation artifacts that typically overwhelm sensitive readout circuits. The proposed system utilizes a time-multiplexed readout combined with backend linear interpolation to reconstruct artifact-corrupted LFP features, offering an alternative to power-intensive readout architectures and complex artifact cancellation circuits. Implemented in a 180-nm CMOS process, the prototype frontend achieves an ultra-compact footprint of 0.0018 mm²/channel and consumes only 4.51 µW/channel, while delivering a peak total harmonic distortion of -72.6 dB at a 2.5-mVpp input. The system's artifact tolerance and reconstruction capabilities were validated through experiments, showing relative accuracies above 95% for a set of sixteen commonly used features across various stimulation scenarios. This work represents a significant advancement in the development of closed-loop neuromodulation systems, with the potential to enhance the treatment of neurological conditions such as epilepsy, Parkinson's disease, and stroke by allowing for more targeted and effective interventions.
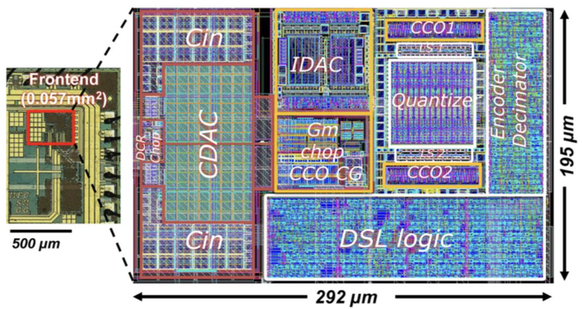
Fig. 6. Micrograph of the neural readout frontend and zoomout of its layout
Paper 3
Barbruni GL, Rodino F, Ros PM, Demarchi D, Ghezzi D, Carrara S. A Wearable Real-Time System for Simultaneous Wireless Power and Data Transmission to Cortical Visual Prosthesis. IEEE Transactions on Biomedical Circuits and Systems. 2024 Jan 23. https://ieeexplore.ieee.org/document/10412337/
Summary: The articl presents a wearable real-time system designed for simultaneous wireless power and data transmission to cortical visual prostheses. The system features a software unit for real-time image processing, a hardware unit for RF signal generation and modulation, and a 3-coil inductive link for power transfer. It operates at a frame rate of 20 Hz, with a carrier frequency of 433.92 MHz, and can communicate with up to 1024 miniaturized neural implants at a data rate of 6 Mbps.
The system is intended for use with cortical visual prostheses that cover a 20-degree visual field and is versatile enough for other applications requiring wireless neural interface communication. The hardware includes a Visual Processing Unit (VPU), Power Management Unit (PMU), and Wearable Transmitting Unit (WTU), which together enable real-time image acquisition, processing, and data transfer. The WTU uses Amplitude Shift Keying (ASK) modulation for efficient power and data transmission.
The inductive link is optimized for operation in both air and ex vivo conditions, with the presence of tissues affecting the quality factor and self-resonance frequency of the coils. The system operates within Specific Adsorption Rate (SAR) limits, ensuring safety for cortical implants. The entire system is packaged in a 3D-printed case and powered by a rechargeable battery, with a total efficiency of ηs.
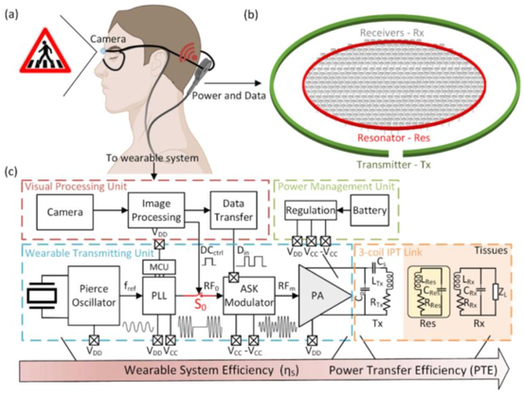
Fig. 1. (a) General overview of a wireless and distributed cortical visual prosthesis. (b) Sketch of a 3-coil inductive link toward multiple miniaturised neural implants. (c) Block diagram of the real-time system for simultaneous wireless power and data transmission including the Visual Processing Unit (VPU, red), the Power Management Unit (PMU, green), the Wearable Transmitting Unit (WTU, blue) and the electrical equivalent model of the 3-coil IPT link (orange), including transmitter coil (Tx), resonator coil (Res), and receiver coil (Rx).
Paper 4
Busia P, Cossettini A, Ingolfsson TM, Benatti S, Burrello A, Jung VJ, Scherer M, Scrugli MA, Bernini A, Ducouret P, Ryvlin P. Reducing false alarms in wearable seizure detection with eegformer: A compact transformer model for mcus. IEEE Transactions on Biomedical Circuits and Systems. 2024 Jan 23. https://ieeexplore.ieee.org/document/10412626/
Summary: This article presents EEGformer, a compact transformer model for wearable seizure detection using EEG signals. The model aims to reduce false alarms and latency, making it suitable for long-term monitoring. Tests on the CHB-MIT dataset show a 20% reduction in latency and a 73% seizure detection probability with 0.15 false positives per hour. The model is designed for efficient execution on low-power micro-controller units, achieving an inference time of 13.7 ms and 0.31 mJ per inference on the GAP9 platform. The study demonstrates the feasibility of deploying EEGformer on wearable seizure detection systems with reduced channel count and multi-day battery duration.
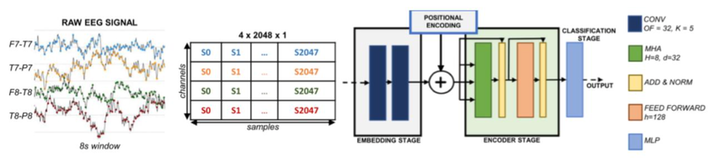
Fig. 1. Architecture of the EEGformer. The Multi-Head-Attention layer is indicated as MHA
Paper 5
Karimi MJ, Jin M, Zhou Y, Dehollain C, Schmid A. Wirelessly powered and bi-directional data communication system with adaptive conversion chain for multisite biomedical implants over single inductive link. IEEE Transactions on Biomedical Circuits and Systems. 2024 Jan 29. https://ieeexplore.ieee.org/document/10416348/
Summary: This paper presents a wirelessly powered and bi-directional data communication system for multisite biomedical implants. The system uses dual-band coils for power and data transfer, supporting ASK and LSK modulation schemes. It includes an active rectifier, resonance tuning system, and power control unit for efficient power transfer. A self-sampling ASK demodulator is proposed for data conversion. The system is fabricated using a standard CMOS process and achieves a maximum power transfer efficiency of 31.2%. The system addresses challenges in powering multiple implants and ensures reliable data communication for therapeutic applications.
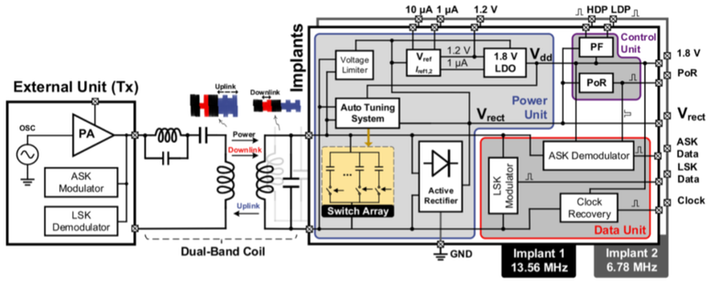
Fig. 1. Block diagram of the proposed wireless power and data transmission system with global power control for the closed-loop biomedical implant.
IEEE Transactions on Very Large Scale Integration (VLSI) Systems
Paper 1
R. Balas, A. Ottaviano and L. Benini, "CV32RT: Enabling Fast Interrupt and Context Switching for RISC-V Microcontrollers," IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 32, no. 6, pp. 1032-1044, June 2024, doi: 10.1109/TVLSI.2024.3377130 https://ieeexplore.ieee.org/document/10477942
Summary: This paper discusses the increasing adoption of RISC-V processors in the embedded world, highlighting their need for real-time constraints, flexibility, predictability, and fast event handling. The paper compares RISC-V processors to more mature proprietary architectures like ARM Cortex-M and TriCore, noting that RISC-V lags in interrupt handling. The standard RISC-V core local interruptor (CLINT) is limited in configurability for interrupt prioritization and preemption. To address this, the RISC-V core local interrupt controller (CLIC) specification introduces preemptible, low-latency vectored interrupts with optional extensions to improve latency. The paper presents the implementation of a CLIC for the CV32E40P, an open-source 32-bit RISC-V core, and its enhancement with a custom extension called fastirq, achieving interrupt latency as low as six cycles. The enhanced core, named CV32RT, is the first fully open-source RV32 core with interrupt-handling features comparable to ARM Cortex-M and TriCore. The extensions also improve task context switching in real-time operating systems (RTOSs).
Paper 2
L. Zhou et al., "Better-Than-Worst-Case: A Frequency Adaptation Asynchronous RISC-V Core With Vector Extension," IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 32, no. 6, pp. 1045-1057, June 2024, doi: 10.1109/TVLSI.2024.3375350. https://ieeexplore.ieee.org/document/10475190
Summary: This paper proposes a fully digital design method for frequency adaptation in asynchronous bundled-data (BD) circuits. The method is straightforward, effective, widely applicable, and independent of asynchronous controllers, allowing automatic frequency adaptation to improve performance and reduce power consumption, achieving better-than-worst-case scenarios. To verify this method, an asynchronous RISC-V processor with a vector acceleration extension was designed using both the TSMC 65-nm process and a field-programmable gate array (FPGA) platform. Postlayout simulation results show that, compared to its synchronous version, the asynchronous processor achieves a 10% speed improvement (from 227.3 to 250 MHz) and a 37% power reduction (from 135 to 85 μW/MHz) under ideal conditions. Even under worst-case conditions, the asynchronous processor matches the synchronous processor's performance while still reducing power consumption by 29% (from 133 to 95 μW/MHz). On the FPGA platform, the asynchronous processor also demonstrates higher speed and lower power consumption.
Paper 3
X. Zheng, M. Cheng, J. Chen, H. Gao, X. Xiong and S. Cai, "BSSE: Design Space Exploration on the BOOM With Semi-Supervised Learning," IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 32, no. 5, pp. 860-869, May 2024, doi: 10.1109/TVLSI.2024.3368075. https://ieeexplore.ieee.org/document/10454021
Summary: This paper highlights the challenge of exploring the vast and complex RISC-V microarchitecture design space. The authors propose the Berkeley Out-of-Order Machine Semi-Supervised Explorer (BSSE) framework which leverages semi-supervised learning and parallel emulation to expedite and optimize the design space exploration of RISC-V microarchitectures. The process begins with constructing an initial training dataset using the microarchitecture experimental design sampling (MEDS) method. It then employs a co-training-style k-nearest neighbors (Co-KNN) model to map microarchitecture features to architectural metric values. The trained Co-KNN model aids in searching for a Pareto-optimal set through parallel emulation. A distance-based method then selects a designer-preferred microarchitecture from this set. Extensive experiments on the Berkeley Out-of-Order Machine (BOOM) demonstrate that BSSE can identify a superior Pareto-optimal set more efficiently than state-of-the-art methods and can find microarchitectures that match or surpass the performance of existing manually designed BOOM microarchitectures.
________________
IEEE Circuits and Systems Magazine Latest Feature Articles: Special Issue on the 75th Anniversary of the IEEE CAS Society

- Past, Present, and Future of CASS Educational Programs and Initiatives
Fakhrul Zaman Rokhani, Xinmiao Zhang, Rajiv V. Joshi, Ricardo Reis, Victor Grimblatt, Kea-Tiong Tang, Yongfu Li, Amara Amara, and Manuel Delgado-Restituto - Superconductive Electronics: A 25-Year Review
Rassul Bairamkulov and Giovanni De Micheli - Cryogenic CMOS Design for Qubit Control: Present Status, Challenges, and Future Directions
Sudipto Chakraborty and Rajiv V. Joshi - PCI-Express: Evolution of a Ubiquitous Load-Store Interconnect Over Two Decades and the Path Forward for the Next Two Decades
Debendra Das Sharma - Fast Settling Phase-Locked Loops: A Comprehensive Survey of Applications and Techniques
Zeeshan Ali, Pallavi Paliwal, Meraj Ahmad, Hadi Heidari, and Shalabh Gupta - A Different View of Sigma-Delta Modulators Under the Lens of Pulse Frequency Modulation
Victor Medina, Pieter Rombouts, and Luis Hernandez-Corporales
______________________________
Latest Tables of Contents of CAS Sponsored Journals
The latest issues of our CAS sponored journals have been published and the tables of contents can be accessed through the following links:

- IEEE Transactions on Circuits and Systems I: Regular Papers
- IEEE Transactions on Circuits and Systems II: Express Briefs
- IEEE Transactions on Circuits and Systems for Video Technology
- IEEE Journal on Emerging and Selected Topics in Circuits and Systems
- IEEE Circuits and Systems Magazine
- IEEE Transactions on Biomedical Circuits and Systems
- IEEE Design and Test Magaz