Our Editors-in-Chief’s Top Picks
The Editors-in-Chief of our CASS publications have selected some noteworthy papers from the recent issues of our journals:
IEEE Transactions on Circuits and Systems I: Regular Papers
Paper 1:
Jin-Seok Heo, Yoona Lee, and Woo-Seok Choi, "A 0.093 pJ/b/dB 20 Gb/s ADC-Based PAM4 Receiver With 33 dB Loss Compensation Using Time-Interleaved Charge-Based Subranging ADC," in IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 73, no. 5, pp. 3068-3080, May 2026, doi: 10.1109/TCSI.2025.3636097.
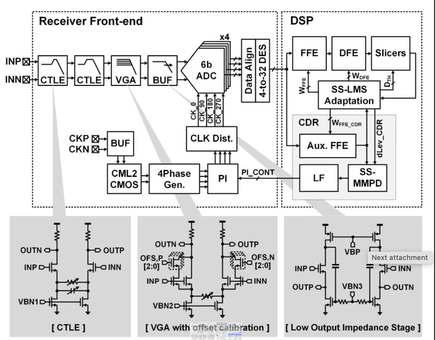
Summary: This paper presents an energy-efficient ADC-based PAM4 receiver fabricated in a 28 nm CMOS process. The proposed design features a four-way time-interleaved charge-based subranging ADC that integrates three key techniques: 1) a wide input-tolerant charge-based comparator that extends the limited input range and improves operational robustness of conventional low-power charge-based comparators, 2) a conditional-branching-based partial activation scheme that improves the area and capacitive efficiency of the subranging architecture, and 3) a time-based calibration technique that addresses potential performance degradation in the conditional branching scheme. These design techniques enable robust and power-efficient ADC operation optimized for high-speed applications while minimizing the interleaving factor. The prototype ADC achieves an SNDR of 29.1 dB (ENOB = 4.54 bits) at 4 GHz input and 8 GS/s. Operating at 20 Gb/s under a 33.1 dB insertion loss channel, the proposed receiver effectively compensates for ISI, achieving a pre-FEC BER of 1.8E-8 with a competitive energy efficiency of 3.09 pJ/b.
Paper 2:
Chen Deng, Wenhua Gong, Yatao Peng, Jun Yin, Jing Wang, Jad Benserhir, Lin Cheng, Edoardo Charbon, Rui P. Martins, and Pui-In Mak, "A Cryogenic HBT-CMOS Temperature Sensor Operating From 4 to 70 K," in IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 73, no. 5, pp. 3102-3115, May 2026, doi: 10.1109/TCSI.2025.3642813.
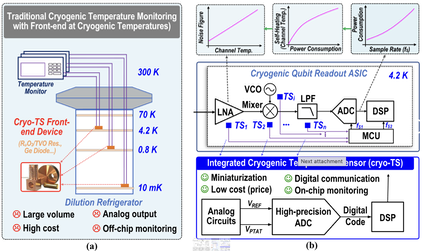
Summary: In current cryogenic temperature sensor (cryo-TS) systems, the sensing front-end and readout circuits typically operate in cryogenic and room-temperature environments, respectively. This paper proposes a scheme to integrate both the front-end devices and readout circuits of cryo-TS within the cryogenic environment to achieve lower noise, digital fan-out of temperature information, and cost reduction. We employed the silicon-germanium (SiGe) heterojunction bipolar transistors (HBT), which demonstrated excellent linearity and current gain even at cryogenic temperatures, as the sensing front end of the cryo-TS and a Zoom-ADC as its readout circuits. A redundancy bit is introduced in the cryogenic readout ADC to avoid temperature misjudgment. The design methodology and key considerations for implementing cryogenic readout analog circuits are presented. Implemented in a 65 nm CMOS process, the cryo-TS achieved a 1-point-trimmed (at 40 K) inaccuracy of ±0.54 K (3σ) from 4 K to 70 K under a supply current of 22.13 μA.
IEEE Transactions on Circuits and Systems II: Express Briefs
Paper 1:
Yizhou Zhao , Xinyu Zhao, Yuan Shen, Chengxiang Zheng, En Zhu, and Yingmei Chen, “A 56-Gb/s 10.46-pA/sqrt_Hz Input Noise Linear TIA With 31-dB Dynamic Range in 22-nm CMOS,” IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 73, no. 4, pp. 448 - 452, Apr. 2026. doi: 10.1109/TCSII.2026.3669591
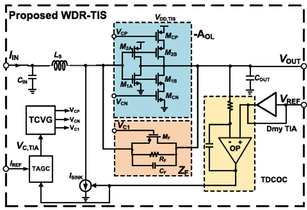
Summary: The rapid growth of AI and cloud services demands optical interconnects capable of transmitting data beyond 56 Gb/s. At the core of these links is a transimpedance amplifier, which converts optical signals into electrical signals. Our design introduces a novel wide dynamic range TIA that allows to dynamically adjust its operating point, maintaining a stable bandwidth even when the input optical power varies by more than 30 dB. Fabricated in a standard 22-nm CMOS process, it achieves an input-referred noise density of just 10.46 pA/√Hz together with high linearity. This work enables optical receivers that are both highly sensitive to weak signals and robust enough to handle strong ones, contributing to more efficient data centers.
Paper 2:
Jingbin Feng , Shanshan Zhou , Peiru Hou, Pengda Qu , Yue Zhao , and Zhiming Xiao, “A 60-V Chopper Amplifier Achieving 0.12-uV Ripple and 2-uV VOS Over Full Temperature With Calibration,” IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 73, no. 4, pp. 368 - 372, Apr. 2026. doi: 10.1109/TCSII.2026.3663261
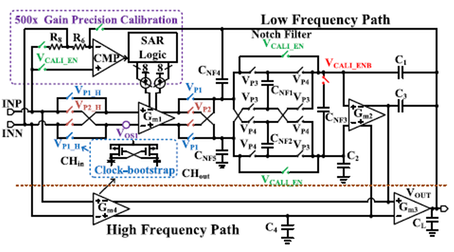
Summary: This work presents a 60 V chopper-stabilized operational amplifier (opamp) with an 8 MHz gain-bandwidth product (GBW) and precision calibration. A high-voltage adaptive clock-bootstrap technique is proposed, compensates for temperature variations of the threshold voltage, and maintains a constant overdrive voltage. The opamp integrates a gain module to amplify and calibrate the non-chopped offset voltage, thereby reducing output ripple. It adopts a calibration scheme with temperature-compensated bit weights which are proportional to the transconductance of the chopper-path input transistor pair. Fabricated in a 0.18- m Bipolar-CMOS-DMOS process, the amplifier employs input-referred offset and ripple minimization techniques while ensuring consistent performance over a wide input common-mode voltage range and temperature span, achieving a 3- offset voltage of V across 100 samples (- C to C), an offset drift of 7 nV/°C, and a maximum input-referred ripple of VRMS(Root Mean Square).
Paper 3:
3. Wanqing Wu , Xinyi Zhang , Ning Zhang, Ruiyong Xiang , Haigang Feng , and Zhihua Wang, “A 16-to-24.9 GHz Dual-Core Dual-Mode Noise-Circulating VCO Using Single-Phase Switch With FOMT of 209.0 dBc/Hz,” IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 73, no. 5, pp. 508 - 512, May. 2026. doi: 10.1109/TCSII.2026.3669392
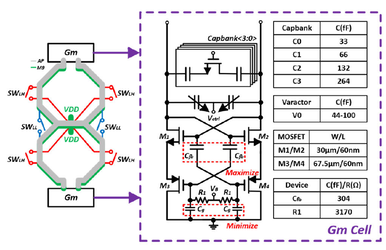
Summary: This work presents a dual-core dual-mode noise-circulating voltage-controlled oscillator (VCO) with a wide frequency tuning range (FTR) and low phase noise (PN) for K-band applications. Specifically, the VCO employs an optimized capacitively coupled noise-circulating structure to operate in the K-band while suppressing the thermal noise contribution of the transistors. Fabricated in a 65-nm CMOS process, the VCO occupies an active core area of 0.096 mm2. When operating at 16.32 GHz, the VCO achieves -148.4 dBc/Hz at 10 MHz offset frequency after the frequency is divided by three. While the power consumption is 4.9 mW from a 0.9 V supply, the resulting figure-of-merit (FOM) is 196.2 dBc/Hz. With a FTR from 16 GHz to 24.9 GHz (43.5%), the VCO achieves a FOM with tuning range (FOM ) of 209.0 dBc/Hz.
IEEE Transactions on Circuits and Systems for Video Technologies
Paper 1:
Yimin Fu, Runqing Yang, Zhunga Liu, Michael K. Ng. "Adaptive Mixture-of-Experts Distillation for Cross-Satellite Generalizable Incremental Remote Sensing Scene Classification," IEEE Trans. on Circuits and Systems for Video Technology, vol.36, no.1, pp.233-247, Jan. 2026. doi: 10.1109/TCSVT.2025.359827.

This paper proposes adaptive mixture-of-experts distillation (AMoED) for cross-satellite generalizable incremental remote sensing scene classification (CS-GIRSSC). Specifically, AMoED adopts a high-level semantic learning pipeline, in which new knowledge is acquired through the coordinated guidance of multiple domain-specific experts, rather than directly from raw data. This pipeline prevents the model from being exposed to large volumes of newly emerging data, thereby alleviating the erasure of previous knowledge when adapting to new data distributions. Besides, the adaptive mixture of domain-specific experts facilitates the formation of universal class concepts, which exhibit strong generalizability across different domains. During the learning process, an equi-partite subset is constructed for knowledge acquisition and consolidation, accompanied by a shallow style-mixing operation to mitigate the interference of domain discrepancies. Extensive experiments have been conducted on four remote sensing scene classification datasets, and the method proposed in this paper consistently shows state-of-the-art performance across various scenarios and settings. The code has been also made available by the authors at https://github.com/fuyimin96/AMoED
Paper 2:
Xiao Wang, Chao Wang, Shiao Wang, Xixi Wang, Zhicheng Zhao, Lin Zhu. "MambaEVT: Event Stream-Based Visual Object Tracking Using State Space Model," IEEE Trans. on Circuits and Systems for Video Technology, vol.36, no.1, pp.278-291, Jan. 2026. doi: 10.1109/TCSVT.2025.3588533.
This paper proposes a Mamba-based visual tracking framework that adopts the state space model with linear complexity as a backbone network. The search regions and target template are fed into the vision Mamba network for simultaneous feature extraction and interaction. The output tokens of search regions will be fed into the tracking head for target localization. More importantly, a dynamic template update strategy is introduced into the tracking framework using the Memory Mamba network. By considering the diversity of samples in the target template library and making appropriate adjustments to the template memory module, an effective dynamic template can be integrated. The effective combination of dynamic and static templates allows the proposed Mamba-based tracking algorithm to achieve a good balance between accuracy and computational cost on multiple large-scale datasets, including EventVOT, VisEvent, and FE240hz. The source code and checkpoint of this work have been released on https://github.com/Event-AHU/MambaEVT

Overview of the proposed pure Mamba-based visual object tracking using an event camera, termed MambaEVT. The vision Mamba based backbone network performs feature extraction, interaction and fusion, simultaneously. It ensures the tracker achieves good performance and lowers computational cost. The learnable Memory Mamba for dynamic template generation makes the tracker more robust to significant appearance variation.
Paper 3:
Nian Wang, Zhigao Cui, Yanzhao Su, Yunwei Lan, Yuanliang Xue, Cong Zhang. "Weakly Supervised Image Dehazing via Physics-Based Decomposition," in IEEE Trans. on Circuits and Systems for Video Technology, vol.36, no.1, pp.637-652, Jan. 2026, doi: 10.1109/TCSVT.2025.3596024.
This paper proposes a weakly supervised image dehazing (WSID) model via physics-based decomposition (PBD). The proposed approach estimates atmospheric light, scattering coefficient and scene depth of real haze input to effectively capture the illumination information and haze distribution to recover a preliminary dehazed image by minimizing reconstruction loss. With this constraint, a subtly discrete wavelet discriminator (DWD) is designed to effectively improve the generalization to real scene from both spatial and frequency aspect under the supervision of unpaired real clear image. The PBD is a purely data-driven model freeing from any manual setting or partially correct prior, thus simultaneously ensuring the realness and visibility of dehazed images. Experiments on seven benchmarks have been reported in the paper showing the strong generalization ability of the proposed PBD, which achieves SOTA dehazing performance with realistic details. The code has been made available by the authors at the following link at https://github.com/NianWang-HJJGCDX/PBD

Workflow of the PBD proposed in this paper. First, four generators are used to yield the dehazed image Jout, scattering coefficient β, scene depth D, global atmospheric light A. The β and D capture the haze distribution of input real haze image Ireal and obtain a refined transmission map T. Reconstruction loss is used to constrain the structure information of these parameters. Then DWD improves the generalization ability of Jout and makes it fit in various real haze scenes via the adversarial training from both spatial and frequency aspect.
IEEE Transactions on Very Large Scale Integration (VLSI) Systems
Paper 1:
Das, S., Riedel, S., Naeim, M., Brunion, M., Bertuletti, M., Benini, L., Ryckaert, J., Myers, J., Biswas, D. and Milojevic, D., 2024. "Bandwidth-Latency-Thermal Co-Optimization of Interconnect-Dominated Many-Core 3D-IC," IEEE Transactions on Very Large Scale Integration (VLSI) Systems. vol. 33, no. 2, pp. 346-357, Feb. 2025, doi: 10.1109/TVLSI.2024.3467148 https://ieeexplore.ieee.org/document/10720515
Summary: The article addresses the challenges faced by contemporary system-on-chips (SoCs) due to the increasing demands for memory bandwidth, capacity, and thermal stability, particularly in the context of advancing artificial intelligence (AI). It proposes architectural modifications for a many-core SoC designed to enhance on-chip cache memory bandwidth and optimize access latency. The SoC is fabricated using A10 nanosheet technology in a 3-D configuration, with thermal analyses conducted. Workload simulations demonstrate significant performance improvements, achieving up to 12-fold acceleration for a 64-core version and 2.5-fold for a 16-core version, accompanied by a 40% increase in die area and a 60% rise in power dissipation when using a 2-D design. In comparison, the 3-D design not only minimizes the physical footprint but also saves 20% in power consumption due to a 40% reduction in wirelength. The study emphasizes the importance of restructuring pipelines to optimize the benefits of 3-D technology for enhanced memory access and lower latency. Additionally, it explores thermal impacts of different 3-D partitioning approaches in high-performance computing (HPC) and mobile applications, finding that 3-D designs in mobile contexts only slightly increase maximum temperature (by about 2-3 °C) compared to 2-D, while HPC scenarios require careful partitioning strategies to effectively manage thermal constraints.
Paper 2:
G. Murali, M. Gyu Park and S. Kyu Lim, "3DNN-Xplorer: A Machine Learning Framework for Design Space Exploration of Heterogeneous 3-D DNN Accelerators," IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 33, no. 2, pp. 358-370, Feb. 2025, doi: 10.1109/TVLSI.2024.3471496. https://ieeexplore.ieee.org/document/10715720
Summary: This paper introduces 3DNN-Xplorer, a novel machine learning (ML)-based framework for predicting the performance of heterogeneous 3-D deep neural network (DNN) accelerators. This framework enables design space exploration (DSE) of these accelerators with a two-tier compute-on-memory (CoM) configuration, considering 3-D physical design factors. The framework explores four distinct heterogeneous 3-D integration styles combining 28-nm and 16-nm technology nodes for both compute and memory tiers. Through extrapolation techniques and ML models trained on various accelerator configurations, the performance of larger systems is estimated, achieving a maximum absolute error of 13.9%. The framework considers area imbalance arising from different technology nodes by assuming equal numbers of PEs or on-chip memory capacity across integration styles. The analysis reveals that the heterogeneous 3-D style with 28-nm compute and 16-nm memory demonstrates energy-efficient performance, offering up to 50% energy savings and an 8.8% reduction in runtime compared to other 3-D integration styles. Conversely, the heterogeneous 3-D style with 16-nm compute and 28-nm memory proves area-efficient, exhibiting up to 8.3% runtime reduction compared to other 3-D styles.
Paper 3:
A. Almeida da Silva, L. Nogueira, A. Coelho, J. A. N. Silveira and C. Marcon, "Securet3d: An Adaptive, Secure, and Fault-Tolerant Aware Routing Algorithm for Vertically–Partially Connected 3D-NoC," IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 33, no. 1, pp. 275-287, Jan. 2025, doi: 10.1109/TVLSI.2024.3500575 https://ieeexplore.ieee.org/document/10766899
Summary: This article presents Securet3d, a novel routing algorithm designed for multiprocessor systems-on-chip (MPSoCs) that utilize 3-D networks-on-chip (3D-NoCs), aimed at enhancing secure and fault-tolerant operations. As MPSoCs play a crucial role in achieving effective parallel computing by sharing resources across complex applications, implementing adaptive mechanisms to safeguard sensitive data is essential. Securet3d builds upon the existing Reflect3d algorithm, introducing a comprehensive mapping scheme for secure data pathways and improving the system’s fault tolerance. The algorithm's effectiveness is validated through comparisons with three other fault-tolerant routing algorithms in vertically-partially connected 3D-NoCs. All algorithms were developed in SystemVerilog and evaluated via simulations using ModelSim, and hardware synthesis was performed with Cadence’s Genus tool. The experimental results indicate that Securet3d not only reduces latency but also enhances cost-effectiveness compared to other methods. Implemented with a 28-nm technology library, Securet3d exhibits minimal area and energy overhead, demonstrating its scalability and efficiency. Moreover, during denial-of-service (DoS) attacks, Securet3d maintains relatively stable average packet latencies of 70, 90, and 29 clock cycles for uniform random, bit-complement, and shuffle traffic, respectively, which are significantly lower than the latencies observed in other algorithms lacking security mechanisms (5763, 4632, and 3712 clock cycles on average). These findings underscore Securet3d's superior security, scalability, and adaptability for complex communication systems.
IEEE Journal on Emerging and Selected Topics in Circuits and Systems
Paper 1:
Z. Xin, J. Zhang, M. Zhu, Q. Zhong, M. Lei, and B. Hua, "520-Gbit/s Optical-Terahertz Integration System for Cable-Free Data Centers Utilizing Adaptive Bayes-Adam MIMO Nonlinear Equalizer," IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 16, no. 1, pp. 15-26, March 2026, doi: 10.1109/JETCAS.2025.3640639. https://ieeexplore.ieee.org/document/11278661
Summary: To meet the growing demands of next-generation data centers for ultra-high capacity, low latency, and flexible deployment, optical-wireless integrated systems combine the high bandwidth of fiber with the agility of wireless links, enabling scalable and high-speed interconnect solutions. Polarization division multiplexing (PDM) single-input single-output (SISO) links have a simplified architecture design and can double the system capacity through the polarization dimension, but they also introduce more crosstalk and impairments to signal recovery. In this paper, an adaptive Bayes-Adam (ABA) multiple-input multiple-output (MIMO) Volterra nonlinear equalizer (VNE) with high precision and fast convergence is proposed, which better compensates for crosstalk and impairments in dual-polarization (DP) SISO terahertz (THz) transmission systems, including I/Q imbalance, polarization crosstalk, and nonlinear distortion. We experimentally demonstrate a DP-SISO fiber-THz integrated system, which adopts an easily integrable zero-intermediate frequency (Zero-IF) receiver front-end scheme to reduce bandwidth requirements and efficiently receive high baud rate signals. By employing the novel equalization algorithm, we successfully achieve up to 520 Gbit/s single-lane single-carrier wireless air interface rate (WAIR/ch) at 220 GHz with a 20% soft-decision forward error correction (SD-FEC) threshold. This work provides an effective signal processing solution for enabling high-speed, scalable fiber- THz interconnects in future data center networks.
Paper 2:
D. Najafi, H. e. Barkham, Z. Ghanaatian, M. Morsali, H. Chen, T. Das, A. Roohi, P. Mercati, M. Nikdast, M. Imani, and S. Angizi, "Opto-Aligner: Optical Near-Sensor Architecture for Accelerating DNA Pre-Alignment Filtering," IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 16, no. 1, pp. 124-136, March 2026, doi: 10.1109/JETCAS.2025.3619017. https://ieeexplore.ieee.org/document/11196950

Summary: Sequence alignment, a cornerstone application in bioinformatics, is critical for enabling personalized medicine and disease diagnostics. However, the rapid growth of genomic data has led to significant computational challenges, including limited throughput, high latency, and excessive data movement in current sequencing solutions. To address these issues, we propose Opto-Aligner, a high-performance and energy-efficient optical near-sensor accelerator framework tailored for multiple genetic tasks, mainly as DNA/RNA pre-alignment filtering in hyperdimensional space. Opto-Aligner harnesses Silicon Photonics’ promising efficiency and hyperdimensional computing (HDC) robustness to accelerate genome sequence alignment directly at the sensor level. We develop innovative microarchitectural and circuit-level solutions, including specialized hardware partitioning and mapping strategies, to overcome challenges inherent in photonic computing—our cross-layer design accounts for photonic device variability and noise, optimizing HDC algorithms for optical hardware constraints. Opto-Aligner significantly improves throughput and energy efficiency over leading electronic DNA aligners. Relative to the best published electronic aligner (BioHD-HAM), Opto-Aligner delivers a 5.7× higher single-die throughput (0.93 Mb s−1 vs. 0.163 Mb s−1) and a 3.0×10 5 -fold reduction in energy–delay product, all with sub-nanosecond comparator latency and seamless scaling to multi-bit precision. Opto-Aligner effectively bridges the gap between the computational demands of genome alignment and the limitations of optical hardware.
Paper 3:
R. Asquini, A. Buzzin, B. Alam, A. Ceschini, A. Rosato and M. Panella, "All-optical AND Logic Gate With High Extinction Ratio for Neural Network Hardware Implementation," IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 16, no. 1, pp. 106-114, March 2026, doi: 10.1109/JETCAS.2025.3623865. https://ieeexplore.ieee.org/document/11208673
Summary: The development of optical logic gates suitable for multi-stage processes is a central issue in emerging computational applications such as optical neural networks. In this work, we introduce and analyze a scheme for an all-optical AND logic gate, which allows achieving an almost ideal extinction ratio, a feature that simplifies cascaded architectures for complex operations such as multibit sums and multiplications. We analytically demonstrate how our scheme forces three logical states, namely ‘00’, ‘11’ and ‘10’, to be necessarily ideal in behavior. We also outline the conditions for ideal behavior of the remaining logical state ‘01’, which requires the use of semiconductor optical amplifiers (SOA) in their non-linear operations, by tuning the optical input and feeding current. Our numerical analysis on symmetrically balanced SOAs shows that there are multiple conditions enabling a very small output at logical ‘01’; also, our results suggest that those solutions are strongly influenced by the phase shifts induced in SOAs, which requires to avoid small α factors. The performance outlined in our transitions are promising for the implementation of universal gates to be deployed in future architectures for neural optical computation.
IEEE Open Journal of Circuits and Systems
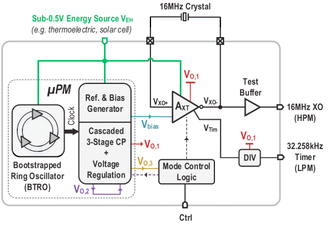
Paper 1:
T. Kaiser, E. Gottschalk, K. Biethahn and F. Gerfers, "Pasithea-1: An Energy-Efficient Sequential Reconfigurable Array With CPU-Like Programmability," IEEE Open Journal of Circuits and Systems, vol. 6, pp. 1-13, 2025, doi: 10.1109/OJCAS.2024.3518110. https://ieeexplore.ieee.org/document/10802954
Summary: This work presents Pasithea-1, a coarse-grained reconfigurable array (CGRA) that combines energy efficiency with CPU-like programmability.
Paper 2:
B. Yang, T. Caldwell and A. Chan Carusone, "An Energy-Efficient Pipeline-SAR ADC Using Linearized Dynamic Amplifiers and Input Buffer in 22nm FDSOI," IEEE Open Journal of Circuits and Systems, vol. 6, pp. 50-62, 2025, doi: 10.1109/OJCAS.2024.3509746. https://ieeexplore.ieee.org/document/10774063
Summary: This work presents a dynamic amplifier that achieves −52 dB in total harmonic distortion through an analog technique by which the expanding and compressing nonlinearities in the input transistors cancel one another. A pipeline-SAR analog-to-digital converter incorporating the linearized dynamic amplifier in both the input buffer and the first residue amplifier stage was designed and fabricated using the GlobalFoundries 22nm fully depleted silicon-on-insulator process.
Paper 3:
S. Nowshin Chowdhury, M. Chen and S. Shah, "Analysis and Verilog-A Modeling of Floating-Gate Transistors," IEEE Open Journal of Circuits and Systems, vol. 6, pp. 63-73, 2025, doi: 10.1109/OJCAS.2024.3524363. https://ieeexplore.ieee.org/document/10818976
Summary: This work presents a Verilog-A model based on empirical measurements for a floating-gate transistor fabricated using a 65 nm CMOS process.
________________
IEEE CAS Magazine Second Quarter Issue 2026

IEEE Circuits and Systems (CAS) Magazine publishes original review articles and other articles that are of broad interest to the Circuits and Systems Society community. Interested authors are invited to send a three to four page White Paper first to the Editor-in-Chief, Prof. Keshab K. Parhi, by email here. If invited, they can submit a Full Paper at the Author Portal at the link below. CAS Magazine will continue to publish articles related to CAS Society Outreach. In addition, CAS Magazine also publishes articles related to education (such as tricks in solving problems and short lecture notes), conference highlights, chapter highlights, applications, and standards. Please feel free to submit articles that are of broad interest to the members of the CAS Society. For more information, please visit the IEEE Circuits and Systems Magazine on the CASS website.
________________
Call for Papers: IEEE Journal of Selected Topics in Signal Processing (JSTSP) Special Issue on "Autonomous and Evolutive Optimization in Networked AI"
The IEEE Journal of Selected Topics in Signal Processing (JSTSP) is inviting submissions to a special issue on "Autonomous and Evolutive Optimization in Networked AI”.
The issue focuses on autonomous optimization algorithms, evolutive learning, networked AI systems, and their applications in signal processing, communications, AI, and embedded systems.
Submission deadline: June 15, 2026. Please click here for details.
________________
Active "Call for Papers” Archive

______________________________
Latest Tables of Contents of CAS Sponsored Journals
The latest issues of our CAS sponored journals have been published and the tables of contents can be accessed through the following links:

- IEEE Transactions on Circuits and Systems I: Regular Papers
- IEEE Transactions on Circuits and Systems II: Express Briefs
- IEEE Transactions on Circuits and Systems for Video Technology
- IEEE Journal on Emerging and Selected Topics in Circuits and Systems
- IEEE Circuits and Systems Magazine
- IEEE Transactions on Biomedical Circuits and Systems
- IEEE Design and Test Magaz